
Déployer API Platform sur Kubernetes quand on ne l’a jamais fait – partie 4
Publié le 18 juillet 2023
Version utilisée : 3.1
Attention : Ce ne sera pas facile.
Connaitre le fonctionnement de API Platform n’est pas un pré-requis. Si vous n’avez jamais fait de Docker, pas de souci, je récapitule quelques concepts et fondamentaux lorsque je trouve que c’est nécessaire. Je vais les précéder du symbole :
- Comprendre l’architecture de la distribution API Platform
- Démarrer le projet avec Docker Compose
- Comprendre Kubernetes et l’usage de Helm proposé par API Platform
- Déployer localement avec Minikube
- Déployer sur un vrai Cluster
Dans la partie 3 nous avons appréhendé les concepts apportés par Kubernetes. Pour travailler, il existe des outils permettant de déployer un cluster localement, voyons ensemble le cas de Minikube.
Déployer localement avec Minikube
Créer localement un cluster tel que celui vu précédemment pour tester son application est très lourd, et pour certains, irréalisable ! Il vous faudrait un ordinateur de compétition. En effet, sur un projet un peu plus conséquent que la distribution de base d’API Platform, même vos environnements de développement se trouveront sur un véritable cluster.
Pour le reste il y a Minikube ou encore le projet k3s, c’est l’ensemble des processus Manager et Worker dans un seul unique Node, possédant également un Docker Container Runtime installé.
Ce Node est censé être une machine physique, ici on utilisera le système de virtualisation disponible sur la machine.
Installation
Commencez par suivre la procédure d’installation adaptée à votre environnement sur https://kubernetes.io/fr/docs/tasks/tools/install-minikube/.
Par défaut, l’installation vient avec kubectl, l’outil de ligne de commande de Kubernetes (le moyen le plus puissant de manipuler Kubernetes, puisqu’il permet d’absolument tout faire sur votre cluster)
La commande kubectl devrait fonctionner.
Ainsi que la commande minikube

Celle-ci vous affiche les commandes pour manipuler le cluster. Démarrons-le avec la commande `minikube start –addons registry –addons dashboard.
En plus de démarrer Minikube, la commande charge un registry et un dashboard.
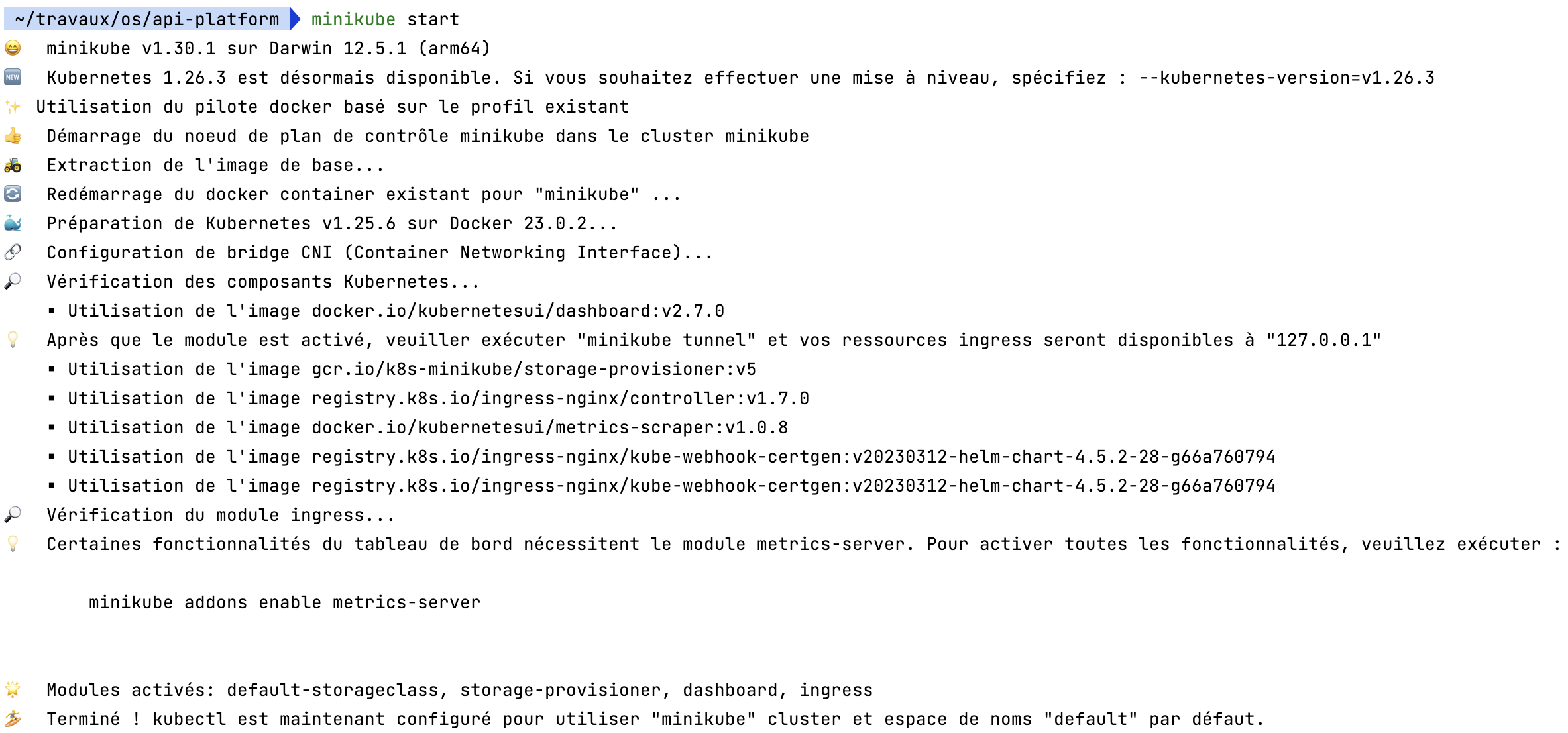
La dernière ligne du terminal m’indique que ma commande kubectl est configurée pour utiliser Minikube. C’est-à-dire qu’elle est paramétrée pour envoyer les requêtes sur l’API Server de Minikube, pas d’un autre cluster. Ainsi que dans l’espace de nom default.
Si vous avez plusieurs équipes, avec chacune des applications similaires et architectures similaires. En tant qu’administrateur système, il est plus agréable de gérer un seul cluster Kubernetes. Alors pour isoler les équipes et éviter des conflits de nom ou de ressources, il est possible de tout séparer à l’aide d’espaces de nom.
Par défaut, un Node existe.

Le Control Plane, bien entendu. On y retrouve le nécessaire pour manipuler le cluster.

À présent, il va falloir créer les images de nos services, et les enregistrer quelque part pour que Minikube puisse les utiliser et créer des pods à partir de celles-ci. C’est le rôle du module registry ajouté au démarrage.
Pour commencer, il y a 3 images à créer, celle de Caddy pour intercepter les requêtes HTTP, celle de l’API, et celle de la PWA.
docker build -t localhost:5000/php api --target app_php
docker build -t localhost:5000/caddy api --target app_caddy
docker build -t localhost:5000/pwa pwa --target prodOn a fait attention de ne pas inclure les stages dédiés au développement. C’est pourquoi on les nomme à l’aide d’un tag. Par la suite, il faudra utiliser l’option -t pour pouvoir les cibler. Et enfin, maintenant qu’elles sont créées, on les envoie sur le registry.
docker push localhost:5000/php
docker push localhost:5000/caddy
docker push localhost:5000/pwa
Si vous avez cette erreur Get "http://localhost:5000/v2/": dial tcp [::1]:5000: connect: connection refused : alors c’est probablement parce que des instructions supplémentaires sont nécessaires pour pouvoir communiquer avec le registry. Voir : https://minikube.sigs.k8s.io/docs/handbook/registry/#docker-on-macos
Notre application est prête à être déployée, il nous reste à faire deux choses. L’installer sur le cluster, puis nous ouvrir un accès.
Pour l’installer, nous pourrions utiliser toutes les commandes offertes par kubectl pour créer les pods un à un, définir leur configuration, etc. Mais pour nous simplifier le travail et faire le tout en quelques lignes de commande, API Platform nous prémâche le travail avec Helm.
Avant de vous montrer les commandes, voici un petit récapitulatif de ce qu’offre Helm. Cependant, je ne m’attarderais pas sur les détails, pour la simple raison que Helm évolue de façon très importante d’une version à l’autre. Ici, comprendre les principes est plus important.
Helm
Helm, c’est un moteur de gabarit. En principe, pour déclencher le déploiement d’un objet de Kubernetes dans notre cluster, il faut avoir un fichier qui décrit cet objet. Le moteur de gabarit est là pour nous aider à rendre ces fichiers de configuration dynamiques. Étant donné que vous risquez de devoir les lire, et qu’ils peuvent être déstabilisants, prenons le temps de regarder leur composition.
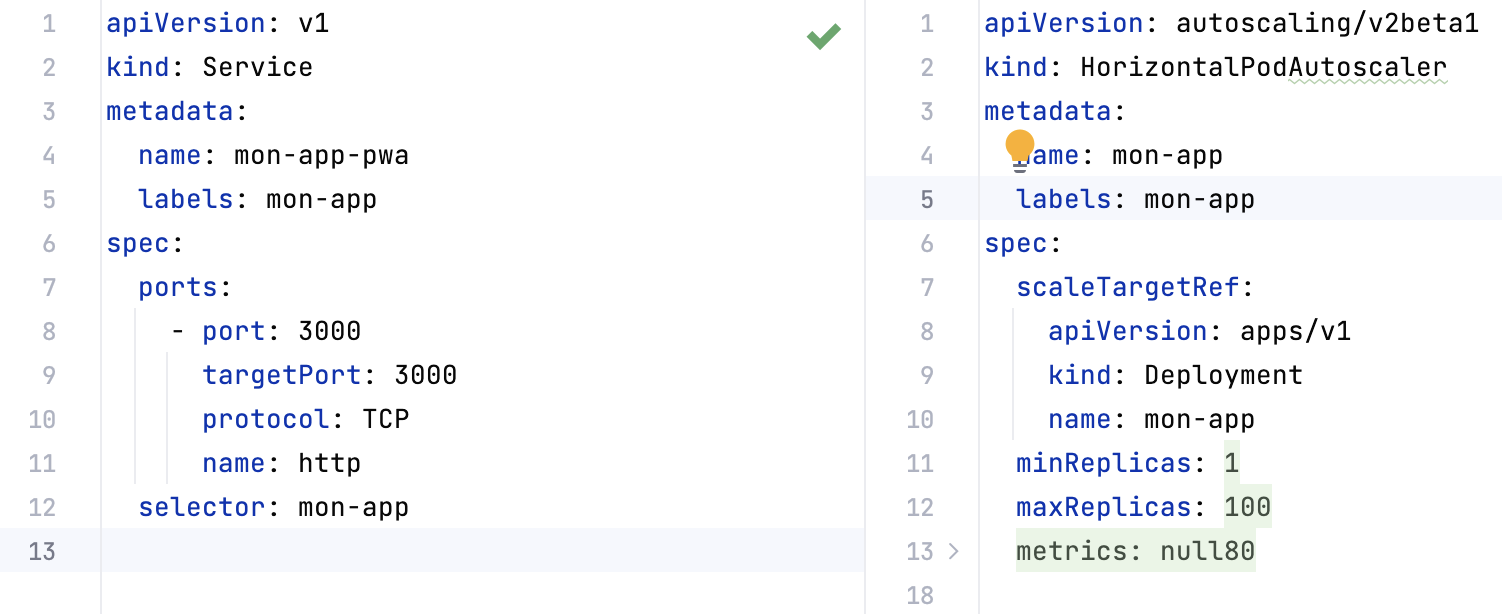
Dans tous ces fichiers, nous trouvons d’abord le type d’objet que nous créons. Défini par la clé kind. Ici, nous avons deux fichiers de configuration pour deux objets différents. Un Service et un HorizontalPodAutoscaler, pour détecter s’il est nécessaire d’ajouter un pod de plus pour supporter la charge en cours.
Ensuite, une clé metadata, dans laquelle se trouve par exemple le nom du service.
Puis une clé de spécification (spec), où se trouvent toutes les configurations à appliquer sur cet objet / composant. Son contenu sera différent selon le kind défini. Il faudra aller voir la documentation de ce type d’objet pour connaître les options qu’il offre.
Et enfin, ces fichiers contiennent une dernière clé nommée statuts. Cependant, si vous ne la voyez pas dans la capture d’écran, c’est parce qu’elle sera générée et ajoutée automatiquement par Kubernetes. Cette clé permet de comparer l’état désiré par nos options et l’état actuel, afin d’agir et modifier le cluster en fonction de nos demandes. Ce qui fait entre autres partie des moyens d’autoréparation de Kubernetes. Enfin, ce statut sera stocké par l’objet Etcd vu plus tôt.
Un cas particulier de définition d’objet comme le Deployment possède plusieurs niveaux. Puisqu’il sert à manager des Pods, il doit aussi contenir une configuration de pods.
apiVersion: apps/v1
kind: Deployment
metadata:
name: caddy-deployment
labels:
app: mon-app-caddy
spec:
replicas: 1
selector:
matchLabels:
app: mon-app-caddy
template:
metadata:
labels:
app: mon-app-caddy
spec:
# ...Dans la clé template, on retrouve une configuration dans une configuration.
Je n’ai pas encore évoqué les clés labels et selector qui servent à connecter tous nos objets. C’est pour cela que les metadata contiennent les labels et les spécifications contiennent les sélecteurs (de label). Un label est une association clé:valeur de votre choix. Ici app: mon-app-caddy pour nommer nos Pods et notre Deployment, puis à l’aide du sélecteur, faire le lien entre eux.
Enfin une dernière partie qui me semble importante, ce sont les ports. Lorsqu’une requête HTTP arrive auprès d’un service, ce dernier doit savoir où et comment la rediriger sur les pods auxquels il est associé. C’est pourquoi sur un Deployment, la configuration de Pod définira le port exposé de son conteneur. En conséquence, sur un Service, nous définirons le port qu’il écoute et le port cible (targetPort) sur lequel rediriger la requête.
—
À présent que ces fichiers sont plus clairs, vu leur complexité et alors qu’on pourrait avoir une configuration prête à l’emploi nécessitant juste quelques personnalisations minimes autant en profiter, d’autant plus que c’est ce qu’offre API Platform. Avec Helm !
Dans la distribution, tout se trouve dans le répertoire helm/api-platform.
La structure d’un répertoire pour helm est toujours la même, c’est d’abord un niveau pour chaque application à déployer. Ici :
helm/
api-platform/ <- top level - c'est le nom du chart
Chart.yaml <- metadonnées (nom, version, dépendances)
values.yaml <- valeurs pour les gabarits
charts/ <- les charts des dépendances viennent là
gabarits/ <- nos gabaritsDans les gabarits, nos fichiers seront des configurations d’objets Kubernetes au format YAML. Pour proposer des noms d’applications et ports différents, les valeurs sont remplacées par des placeholders {{ PLACEHOLDER }}.
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "api-platform.fullname" . }}
labels:
{{- include "api-platform.labels" . | nindent 4 }}
template:
metadata:
{{- with .Values.podAnnotations }}
...Ces placeholders proviennent de deux fichiers. _helpers.tpl et values.yml.
Derrière le mot clé .Values.* se trouve un objet constitué des valeurs trouvées dans le fichier values.yml. Et l’on y trouve aussi des instructions pour formater les valeurs obtenues.
On peut aussi le faire avec l’argument --set pour les changer à la volée. C’est très pratique pour le faire dans les pipelines de chaîne d’intégration continue Gitlab ou Github.
Sur ce principe, nous allons pouvoir facilement avoir des configurations pour chaque environnement (dev, preprod, prod…) ou différents clusters.
Chacun ira de sa plume et proposera des charts pour son projet, son entreprise, voir pour toute une communauté ! L’autre aspect de Helm c’est d’être un gestionnaire de packet, en quelque sorte.
Dans la distribution API Platform, nous avons besoin d’une base de données. Et jusqu’ici nous n’avons pas build d’image pour Postgresql. Effectivement, une image ne suffit pas ! Si nous voulions faire tourner un service de base de données dans Kubernetes, il faudrait préparer un Statefulset, un Configmap, le service, le secret, les permissions… En général, 80% de ces opérations sont toujours les mêmes, alors quelqu’un nous aura mis à disposition tout le nécessaire que l’on pourra surcharger pour nos besoins. Cette mise à disposition est faite sous la forme de documents Yaml nommés Helm Charts.
Ce terme n’est pas complètement inconnu puisque nous avons commencé par farfouiller dans le répertoire Helm de la distribution API Platform. Nous avons nos charts, et allons utiliser des charts publics.
Dans notre projet nous retrouvons le fichier ./helm/api-platform/charts.yml
apiVersion: v2
name: api-platform
description: A Helm chart for an API Platform project
home: https://api-platform.com
icon: https://api-platform.com/logo-250x250.png
# Un chart peut être soit un chart application, soit un chart library.
#
# Les charts application sont une collection de modèles qui peuvent être empaquetés dans des archives versionnées pour être déployées.
#
# Les charts library fournissent des utilitaires ou des fonctions utiles pour le développeur de charts. Elles sont incluses en tant que dépendance des charts d'application afin d'injecter ces utilitaires. Les charts library ne définissent aucun modèle et ne peuvent donc pas être déployées.
type: application
# Il s'agit de la version du chart. Ce numéro de version doit être incrémenté à chaque fois apport de modifications au chart et à ses modèles, y compris la version de l'application.
# Les versions sont censées suivre le principe de la version sémantique (https://semver.org/).
version: 0.1.0
# Il s'agit du numéro de version de l'application en cours de déploiement. Ce numéro de version doit être
# incrémenté à chaque apport de modifications à l'application. Les versions ne sont pas censées
# suivre le versionnement sémantique. Elles doivent refléter la version utilisée par l'application.
appVersion: 0.1.0
dependencies:
- name: postgresql
version: ~12.1.14
repository: https://charts.bitnami.com/bitnami/
condition: postgresql.enabledPour pouvoir utiliser Helm, il va falloir l’installer. Vous trouverez toutes les instructions sur cette page.
Pour récupérer le contenu, on va lancer la commande suivante :
helm repo add bitnami https://charts.bitnami.com/bitnami/
helm repo add stable https://charts.helm.sh/stable/
helm dependency build ./helm/api-platform L’infrastructure Helm de la distribution
Dans la distribution, nous allons déployer une architecture très proche de celle-ci :
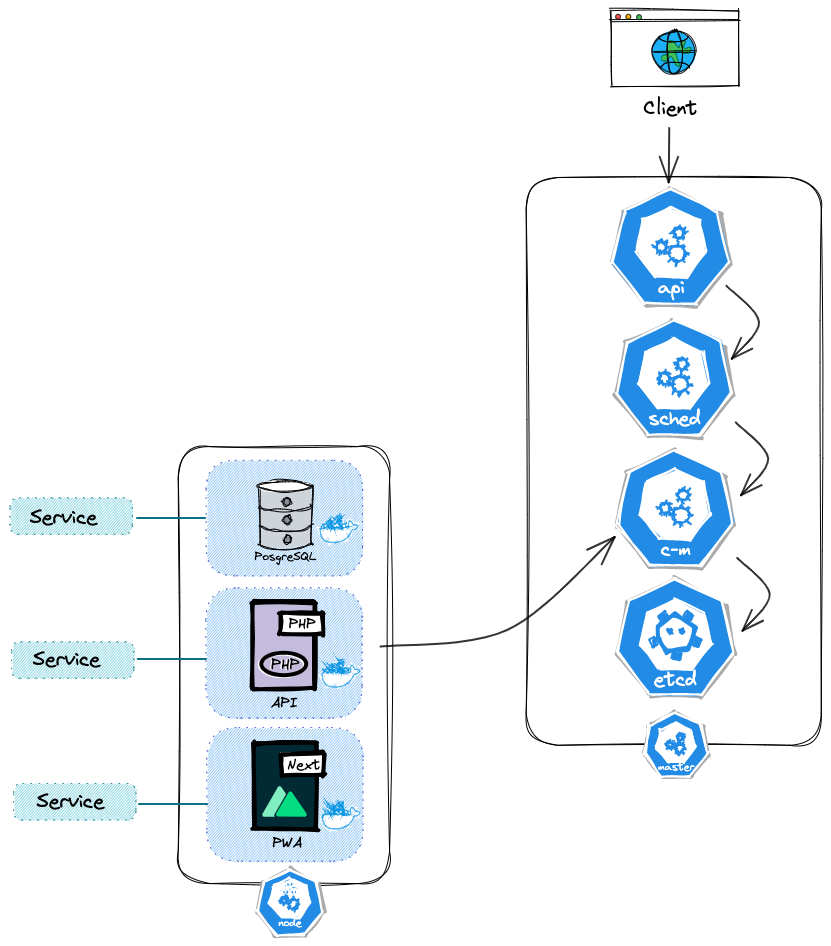
J’ai volontairement omis certains objets Kubernetes présents dans le répertoire. Le ServiceAccount a été évoqué plus haut, et ne nécessite pas d’être représenté pour comprendre ce qui est déployé. Le HPA (HorizontalPodAutoscaler) et l’ingress ne sont pas actifs par défaut.
Déployons sur Minikube.
Déployons notre application avec Helm.
helm install my-project helm/api-platform \
--set php.image.repository=localhost:5000/php \
--set php.image.tag=latest \
--set caddy.image.repository=localhost:5000/caddy \
--set caddy.image.tag=latest \
--set pwa.image.repository=localhost:5000/pwa \
--set pwa.image.tag=latestAlors, techniquement c’est tout bon. SAUF ! Que nous n’avons mis aucun moyen en place d’accéder à notre cluster depuis l’extérieur de celui-ci. Pour le développement en général, faire du port-forwarding suffit, sinon il faudrait mettre en place un objet de type Ingress.
Pour ouvrir un accès de test depuis notre machine vers notre cluster Minikube, Helm nous affiche dans la console, quelques commandes à exécuter.
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=api-platform,app.kubernetes.io/instance=my-project" -o jsonpath="{.items[0].metadata.name}")
export CONTAINER_PORT=$(kubectl get pod --namespace default $POD_NAME -o jsonpath="{.spec.containers[0].ports[0].containerPort}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl --namespace default port-forward $POD_NAME 8080:$CONTAINER_PORTLa première extrait le nom du pod fraichement créé que l’on cible. La seconde le port exposé du conteneur. La commande Echo nous indique où aller sur notre navigateur. La dernière associe le port du conteneur au port 8080.
Tant que celle-ci tourne, nous aurons accès au service via http://127.0.0.1:8080.

Je vous laisse savourer et vous amuser sur les interfaces. Dans le prochain article, nous allons nous pencher sur le déploiement sur un vrai cluster.
Merci de m’avoir lu !
—
Chez Les-Tilleuls.coop, nous utilisons GCP et proposons des offres d’accompagnements Kubernetes. Nos consultants et nos SRE pourront vous accompagner sur vos projets :
Nos offres Cloud et DevOps

