
Déployer API Platform sur Kubernetes quand on ne l’a jamais fait – partie 3
Publié le 18 juillet 2023
Version utilisée : 3.1
Attention : Ce ne sera pas facile.
Connaitre le fonctionnement de API Platform n’est pas un pré-requis. Si vous n’avez jamais fait de Docker, pas de souci. Je récapitule quelques concepts et fondamentaux lorsque je trouve que c’est nécessaire. Je vais les précéder du symbole :
- Comprendre l’architecture de la distribution API Platform
- Démarrer le projet avec Docker Compose
- Comprendre Kubernetes et l’usage de Helm proposé par API Platform
- Déployer localement avec Minikube
- Déployer sur un vrai Cluster
Dans la partie 2, nous avons démarré le projet sous Docker. Pour pouvoir déployer dans Kubernetes, quelques commandes suffisent. Cependant, je préfère éviter l’effet boîte noire / magie de l’outil, alors voyons ensemble ce que vous allez manipuler.
Comprendre Kubernetes et l’usage de Helm proposé par API Platform
Si vous découvrez plus ou moins Kubernetes en me lisant, allez, on prend une grande inspiration… On expire lentement… Et on y va.
Qu’est-ce que Kubernetes ?
Pour commencer, Kubernetes (ou K8s) c’est, au même titre, ce que fait Docker, un outil d’orchestration de conteneurs. Alors attention, on ne joue pas du tout dans la même cour. Il est développé par Google, et propose de gérer vos conteneurs et de les déployer sur des machines physiques, virtuelles ou cloud (ou infonuagiques).
Kubernetes est une réponse aux besoins exprimés par les architectures en microservice. En effet, les conteneurs sont un outil idéal pour des services stateless (une application « stateless » est indépendante, elle ne stocke pas de données et ne fait référence à aucune requête passée). Pour certaines architectures, il peut vous arriver de devoir gérer des centaines de conteneurs, et c’est là que Kubernetes tire son épingle du jeu. Il permet de ne « presque » jamais tomber en panne, ou plutôt de s’autoréparer, d’ajouter et de supprimer des conteneurs à la demande et automatiquement (que l’on paramètrera pour avoir de hautes performances et disponibilités), et possède des mécanismes de sauvegarde et de restauration. Le royaume idéal pour un administrateur système.
Voyons comment sa structure offre de telles promesses avec la distribution API Platform.
Les composants de Kubernetes
Node et Pod
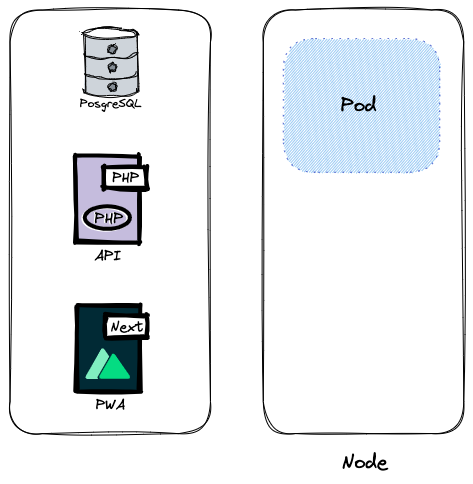
À gauche se trouve ce que l’on doit répartir dans l’univers de Kubernetes. Un Node est un service qui se trouve sur une machine physique ou virtuelle, qu’importe, c’est ce qui se rapproche le plus de ce qu’est un serveur dans le sens classique du terme, mais sans vraiment en être. Techniquement, un serveur peut posséder plusieurs Nodes. Dans notre précédent schéma, ce serait le bloc de Docker en quelque sorte.
Dans un Node se trouvent des Pods. Un pod c’est le plus petit objet de Kubernetes, et c’est une abstraction de ce que l’on nomme conteneur. Le but de cette abstraction c’est de piloter la « vie » d’un ou plusieurs conteneurs via les systèmes de Kubernetes. C’est pourquoi, si demain vous souhaitez passer par une alternative aux conteneurs, du point de vue Kubernetes, vous « discutez » toujours avec un pod.
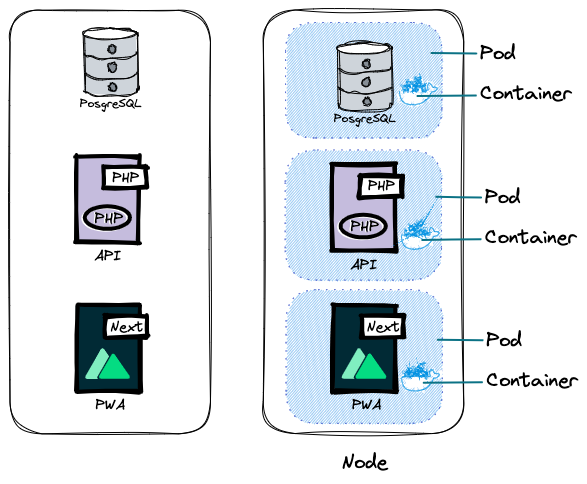
En principe (en dehors de quelques cas avancés, comme les sidecars), un pod contient une application / conteneur, et ces pods, comme nos conteneurs docker, ont une IP éphémère, interne au node. Alors, lorsqu’un conteneur tombe en panne, ou qu’un pod est supprimé ou recréé, la création, l’assignation d’IP et la communication avec les autres pods sont assurées par Kubernetes. Ceci, peu importe la raison, qu’il s’agisse d’une action volontaire ou d’un souci technique.
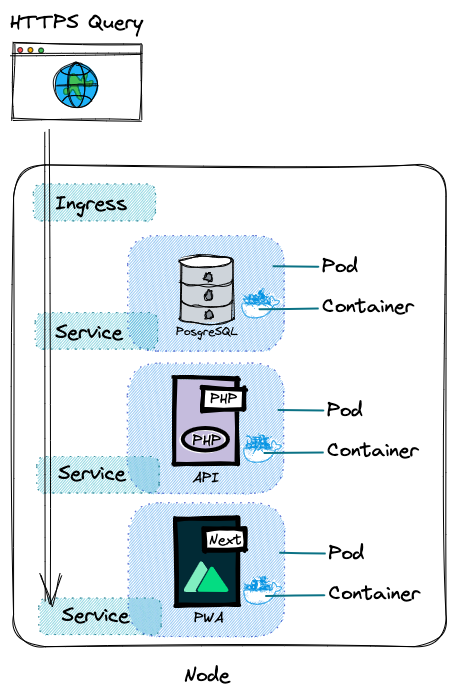
Alors pour nous, humains, ces adresses IP éphémères ne sont pas pratiques, on va travailler avec des noms. Des alias et tags représentant nos applications. Mais avant ça, il faudrait garantir des IP fixes. Pour cela on va réclamer à Kubernetes de créer un objet de type Service.
Un Service aura une IP permanente au sein du node. Si le pod meurt, le service lui continue de vivre, c’est comme ça que l’IP est garantie, les deux sont isolés.
Il existe des Services internes (uniquement accessibles depuis le node) et des Services externes (accessibles depuis l’extérieur). Un Service externe est accessible par un le protocole HTTP, avec une IP et un PORT.
Pour s’assurer que tout fonctionne durant la phase de mise en place de l’architecture, les Services externes sont pratiques, mais nous avons plutôt l’habitude d’accéder à nos applications via un nom de domaine (https://localhost, ). Pour ceci, il faudra utiliser un objet nommé Ingress. Son rôle est de rediriger la requête vers les Services.
Configuration
Lorsque l’on déploie notre application, il va falloir renseigner quelques informations qui seront propres à l’environnement que constitue notre Node. Suis-je en mode dev, ou en mode prod ? Dans quel répertoire envoyer mes fichiers ? Ces informations se trouveront dans un ConfigMap. Le nôtre est présent dans helm/api-platform/templates/configmap.yaml.
Attention, ici, pas de valeurs sensibles comme des clés ou des mots de passe ! Il existe un objet nommé Secrets pour les stocker.
Le nôtre est présent dans helm/api-platform/templates/secrets.yaml.
Stockage
Par défaut, comme avec Docker, tout est stocké localement sur le Pod. S’il meurt, tout est remplacé. Il faut ajouter un volume pour indiquer ou stocker de façon pérenne les données. Il peut être localement sur la machine (node) ou en dehors de votre cluster Kubernetes.
C’est la première fois que j’évoque le terme « cluster ». Kubernetes suppose que l’on gèrera un ensemble de nodes, donc un cluster.
Par défaut, Kubernetes n’est pas du tout conçu pour stocker des données de façon permanente. Essayez systématiquement de penser à ça comme si c’était un disque dur externe.
Haute disponibilité
Pour garantir la haute disponibilité, Kubernetes met à notre disposition une abstraction supplémentaire. Disons que je souhaite avoir tout en deux fois au cas où l’un d’eux tombe en panne.
Nous n’allons plus créer de pods, ou de services manuellement. Si un pod est une abstraction d’un conteneur, un Deployment est en quelque sorte une abstraction d’un pod. Il sera (parmi d’autres usages) responsable de créer et recréer les pods. En cas de panne d’un des services, il s’occupera de rediriger les requêtes vers ceux encore en fonction.
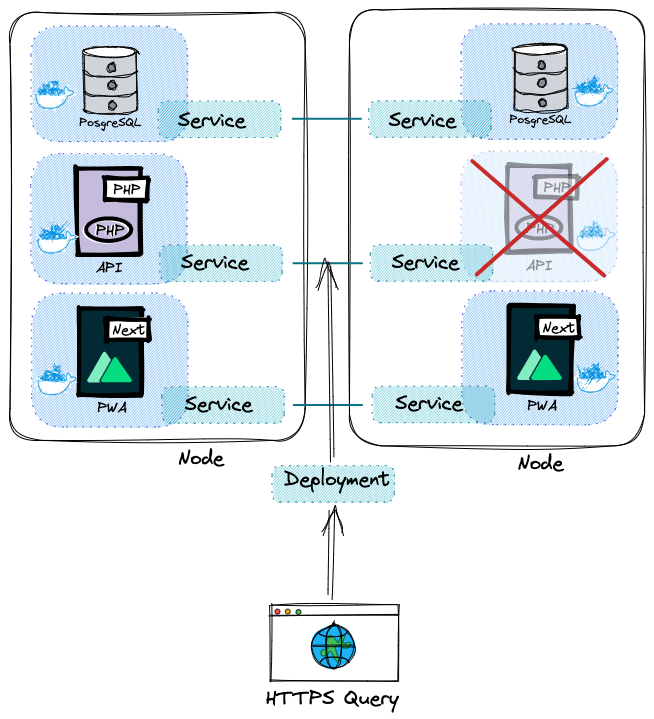
Les nôtres sont présents dans helm/api-platform/templates/deployment.yaml et helm/api-platform/templates/pwa-deployment.yaml ainsi que les Services associés helm/api-platform/templates/service.yaml et, helm/api-platform/templates/pwa-service.yaml. Mais ne passez pas trop de temps à les observer pour le moment, nous les explorerons dans un prochain chapitre.
Pour les services contenant une base de données c’est un peu particulier. En général, nous avons une base de données responsable de l’écriture et de la lecture, et une seconde uniquement responsable de la lecture pour éviter les inconsistances. Pour cet usage, on créera un StatefulSet.
Par prévention, je vous conseille plutôt de travailler avec des bases de données en dehors de votre cluster Kubernetes, parce que gérer des StatefulSet n’est vraiment pas simple. Par chance, nous n’en avons (presque) pas dans notre projet API-Platform.
Voilà qui nous offre un beau tour des éléments de base de kubernetes. Node, Pod, Ingress, Service, Deployment, StatefulSet, Volumes, ConfigMap, Secrets. Ce qui couvre presque tous les fichiers du répertoire helm/api-platform/templates. Il en reste deux : hpa.yaml et serviceAccount.yaml.
D’abord, le HPA (Horizontal Pod Autoscaler) est un objet auquel on demandera de surveiller l’usage des services (mémoire, CPU, bande passante, espace disque, etc.). Nous définirons des seuils qui lorsqu’ils seront franchis déclencheront la création ou la suppression de pods pour s’adapter à la charge.
Ensuite le ServiceAccount, c’est un objet qui nous permet de discuter avec notre cluster et nos services. La commande Kubectl sert pour les humains. Lorsque vous construisez et déployez vos images dans votre Gitlab ou Github avec un agent d’un pipeline, pour des raisons de sécurité, vous allez distinguer les utilisateurs. Le ServiceAccount répond à ce besoin.
Avant de continuer à explorer les autres concepts utilisés dans la distribution, passons un peu de temps à voir une structure classique d’un cluster Kubernetes.
La structure d’un cluster Kubernetes
Un cluster sous Kubernetes se déploie, se répare, crée et supprime des nœuds tout seul. Enfin presque, mais comment ?
Il y a dans un cluster, 2 types de Nodes. Un Control Plane (anciennement Master Node) et des Worker Nodes. Dans les Nodes, en plus de ce que nous y installons en tant que développeurs, il y a quelques objets permettant à tout ce beau monde d’interagir.
Malheureusement, lorsque l’on crée un cluster, ses objets de contrôle ne s’installent pas automatiquement. C’est votre rôle ou celui des SRE (Site Reliability Engineers) de s’en charger. Comme nous allons le voir, ce n’est pas évident, alors si c’est la première fois que vous manipulez Kubernetes, faites appel à une équipe pour vous accompagner dans cette démarche. Si votre projet est encore avec des besoins raisonnables, passez plutôt par une plateforme proposant un cluster Kubernetes managé. Leurs services s’occuperont de ça pour vous.
Dans chacun des Nodes, puisque nous allons utiliser des conteneurs docker, il nous faut un Container Runtime, et tous les Nodes doivent avoir cet objet. Cela dit, il se contente de les faire fonctionner. Celui qui s’occupe de la création des Pods et des conteneurs sous-jacents, c’est le Kubelet. Cet objet-ci peut communiquer avec le Container Runtime et le Node, la machine elle-même.
Les Services évoqués précédemment sont les objets responsables d’attraper les requêtes entrantes pour les envoyer aux Pods adéquats. Et l’objet responsable de cette communication entre Service et Pod s’appelle Kube proxy.
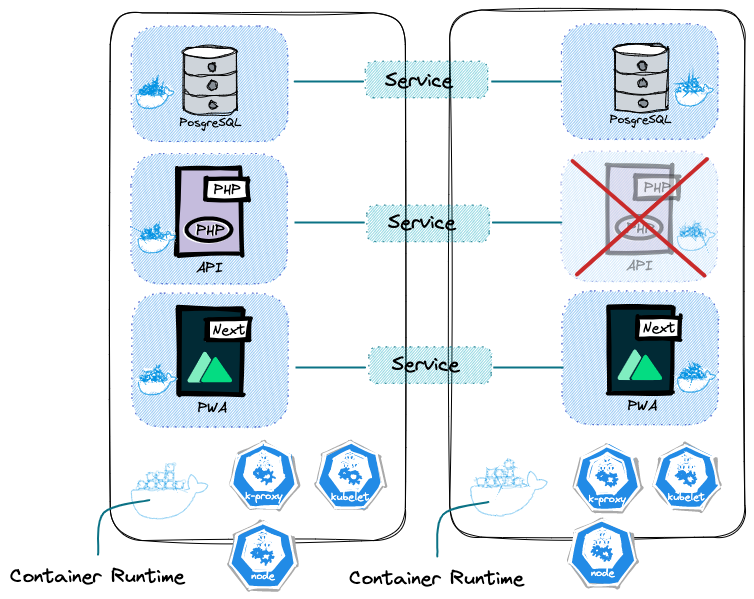
Il faut les installer et les paramétrer sur chaque Node.
Mais ceci ne répond pas à la question suivante : qui se charge de détecter et déclencher le besoin de créer, redémarrer ou supprimer un Pod. De surveiller l’état du cluster, ou encore lorsque l’on rajoute une machine, qu’elle fasse partie du cluster et devienne un Node ? Tous ces processus de « gestion » sont portés par le Control Plane. Celui-ci est différent des Worker Node du précédent schéma. Il contrôle l’état du cluster et contrôle les Worker Nodes.
Dans un Control Plane, il faut installer quatre objets différents de ceux nécessaires pour les Worker Node. En premier lieu, l’API Server. Il est un point d’accès unique au cluster, que ce soit via un tableau de bord, ou la ligne de commande. C’est pourquoi il contrôle que nous soyons bien autorisés à faire la requête.
Ensuite, une fois la requête validée, il peut avoir à contacter un second objet, le scheduler. Son rôle est de définir sur quel Worker Node, un Pod doit être déployé, en comparant les ressources nécessaires pour lui fonctionner et celles disponibles dans chaque Worker Node. CPU, RAM, espace disque, etc. Il contactera le Kubelet du Node.
Puis, lorsque le pod se crée, son existence est transmise au troisième objet, le Controller Manager. Il surveille tout changement d’état dans le cluster. Un pod vient-il de se couper ? Si oui alors il signale au scheduler de le recréer.
Enfin, il nous reste l’ETCD. C’est un système de stockage de type clé:valeur, qui contiendra l’état du cluster. Par exemple les ressources disponibles, l’état d’un node, le nombre de pods, ce qu’ils contiennent, leur configuration, etc. C’est grâce à lui que les objets précédents fonctionnent.
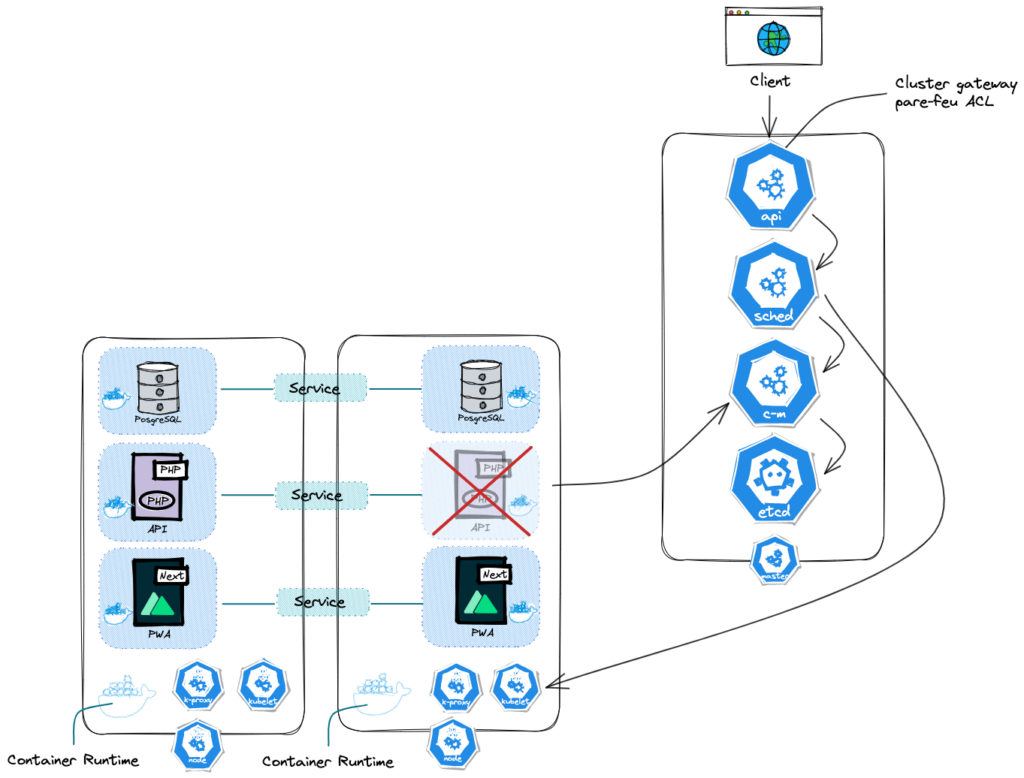
Que se passe-t-il si le Control Plane lui-même cesse de fonctionner ? Et bien c’est la catastrophe, plus rien ne répond.

C’est pourquoi sur un cluster réalisé sérieusement, il y a généralement plusieurs Control Planes, dont l’API Server est derrière un Load Balancer et le Etcd est répliqué sur un système de stockage distribué à travers l’ensemble des Control Plane. Bien qu’importants, en général, ce sont des plus petites machines et leur nombre grandira proportionnellement avec les Worker Nodes.
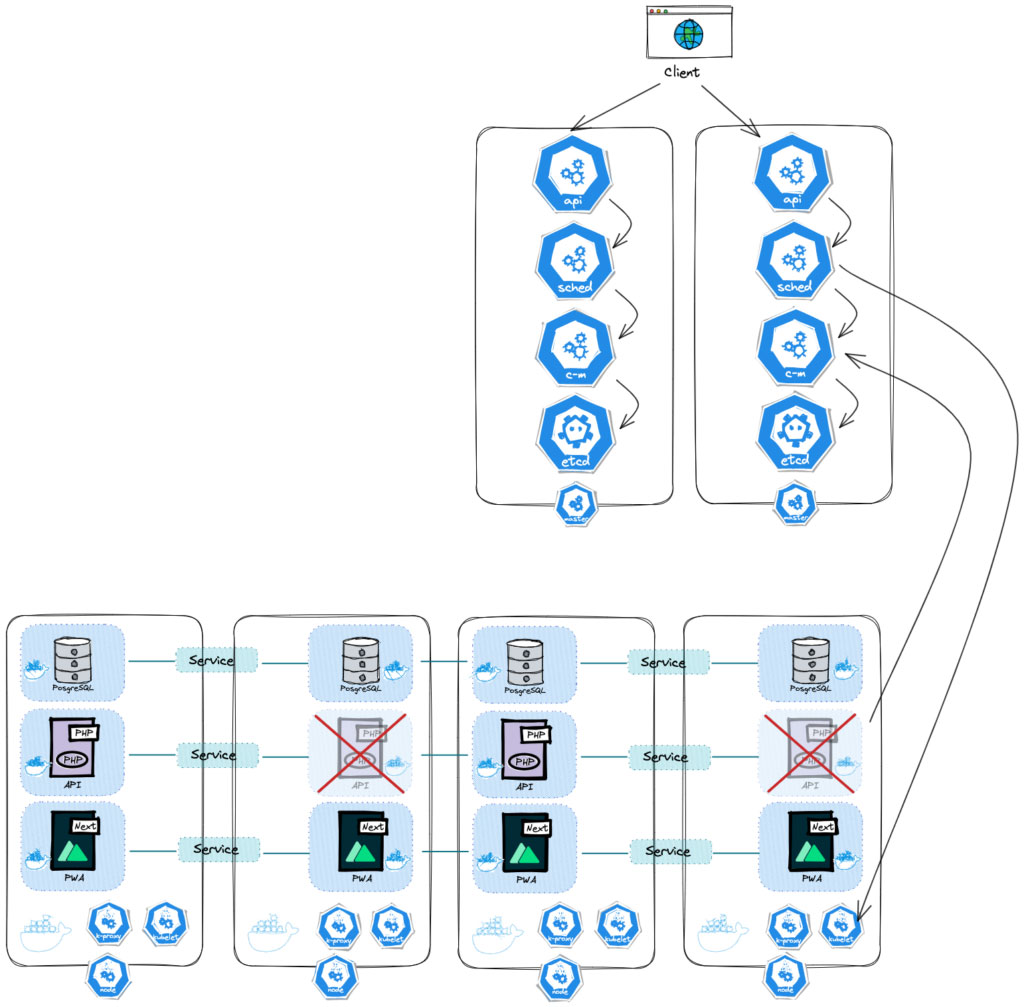
Tout ceci est bien entendu complexe à mettre en place, c’est pourquoi sur vos premières expérimentations, il vaudra mieux opter pour un hébergeur vous proposant un cluster managé. Cela vous offre moins de flexibilité parce que vous n’aurez pas toutes les libertés de configurer votre cluster sur mesure, et certaines infrastructures architecturales seront impossibles, mais en quelques clics il vous sera rendu disponible.
Maintenant que les principes sont ancrés, nous allons pouvoir tester l’infrastructure de la distribution localement, et nous allons utiliser Minikube !
Ce que nous ferons dans le prochain article.
Merci de m’avoir lu.
—
Chez Les-Tilleuls.coop, nous utilisons GCP et proposons des offres d’accompagnements Kubernetes. Nos consultants et nos SRE pourront vous accompagner sur vos projets.
Nos offres Cloud et DevOps

