
Déployer API Platform sur Kubernetes quand on ne l’a jamais fait – partie 1
Publié le 18 juillet 2023
Version utilisée : 3.1
Attention : ce ne sera pas facile.
Connaitre le fonctionnement de API Platform n’est pas un pré-requis. Si vous n’avez jamais fait de Kubernetes ou de Docker, pas de souci. Je récapitule quelques concepts ainsi que des fondamentaux lorsque je trouve que c’est nécessaire. Je vais les précéder du symbole :
- Comprendre l’architecture de la distribution API Platform
- Démarrer le projet avec Docker Compose
- Comprendre Kubernetes et l’usage de Helm proposé par API Platform
- Déployer localement avec Minikube
- Déployer sur un vrai Cluster
Comprendre l’architecture de la distribution API Platform
Bien sûr, il faut commencer par télécharger la distribution. Elle se trouve sur le dépôt GIT https://github.com/api-platform/api-platform. Soit vous passez par le lien de la dernière version et téléchargez le tar.gz, ou bien vous créez un nouveau projet à partir du gabarit proposé par Github.
Nous allons d’abord nous intéresser aux trois répertoires présents (je ne prends pas en compte le fichier .github), et ensuite aux fichiers docker. Avant même d’ouvrir le moindre fichier, nous allons comprendre la structure, et schématiser le flux de nos requêtes HTTP. Ça pourra nous aider en cas d’erreur.
Pour comprendre cette structure, nous allons nous aider de Docker. En particulier du module « compose » et de ses fichiers de configuration. Docker compose nous permet de passer par des fichiers de configuration plutôt que de tout manipuler en ligne de commande, et d’orchestrer notre jeu d’application (notre projet et ses services). Vous n’avez jamais pris le temps de lire un fichier docker-compose ? C’est le moment.
Ouvrons le fichier docker-compose.yml, il contient la configuration de 4 services : php, pwa, caddy, database.
Le module nous offre des commandes pour télécharger des images, auxquelles il sera possible de passer des valeurs pour les préparer avant de les exécuter, voire de les étendre.
Le principe des images est le suivant : imaginez devoir installer un ordinateur. Vous devez sélectionner une distribution linux (ou windows, je ne juge pas) et vous l’installez sur le disque dur de votre machine. Ensuite, vous démarrez et décidez d’ajouter un serveur de base de données PostgreSQL. Alors vous installez le paquet. Durant la procédure, la ligne de commande vous demande de créer un utilisateur root, une base de données et un utilisateur associé. Vous répondez aux questions, c’est terminé, vous avez un ordinateur avec PostgreSQL. Si vous faites une sauvegarde du disque dur tel quel dans un fichier compressé, vous avez l’équivalent d’une image.
De ce point de départ, nous allons ajouter, par couche successive, notre configuration personnelle. C’est le rôle du Dockerfile. Pour nous laisser plus de liberté et garantir la conservation des données, les images peuvent être branchées sur un espace disque externe. C’est le rôle du volume. En faisant cela, PostgreSQL ne voit pas de base de données et va vouloir en créer une lors du premier démarrage. En lui donnant les variables en paramètres, il utilisera nos valeurs pour créer celle-ci.
Une image n’est pas modifiable, pour apporter un changement il faut en créer une nouvelle. Pour les rendre disponibles et les installer, il faut les déposer sur ce qu’on appelle un Registry. Ni plus ni moins qu’un serveur de stockage sur lequel on associe des noms et des versions à des images. Le plus connu est DockerHub. En général, les projets s’appuient surtout sur des Registry privés par souci de stabilité.
Seul le dernier service utilise directement une image, celle de PostgreSQL version 1, tournant sous Alpine. Sans ouverture de port. Les trois autres services sont déclarés dans les répertoires api et pwa. Pour retrouver la définition des images, il faut chercher le fichier Dockerfile dans ces répertoires.
Le Dockerfile sert à la préparation d’une image. Il offre la possibilité de décrire des instructions à exécuter sur la machine pour compléter l’installation, souvent minimaliste. Le but est de réduire le nombre de vecteurs d’attaque. On dit réduire la surface d’attaque. Mais aussi de réduire la taille de l’image pour des raisons d’économie et de performances. Enfin, on peut y adjoindre les bibliothèques ou configurations spécifiques de votre projet. Comme souvent, il faut une version de production et de développement avec nos outils de debug. Alors on va créer des « stages ».
Docker lit puis exécute le fichier de haut en bas. Chaque stage pouvant exploiter le résultat des précédents. Nous allons d’abord définir la configuration de production, puis ajouter des instructions pour le développement. Lors de la création de l’image, nous pourrons préciser le « stage » sur lequel s’arrêter. D’autres règles similaires liées au cache et optimisations de build existent, mais ne sont pas l’objet de ce document.
Pour ne pas m’éparpiller, je vais suivre le parcours d’une requête HTTP. Lorsque nous aurons connecté le tout à internet, le service qui sera responsable de rediriger les requêtes vers l’API, vers un client front (notre « App » ou l’admin), c’est le serveur Caddy.
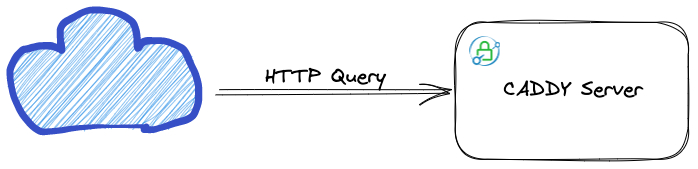
Le serveur Caddy
Dans le fichier docker-compose.yaml, Caddy nous indique en premier lieu qu’il sera construit depuis le Dockerfile du répertoire api, ciblant app_caddy.
caddy:
build:
context: api/
target: app_caddyPuis il explique qu’il attendra le bon fonctionnement des services php et pwa avant de démarrer.
caddy:
build:
context: api/
target: app_caddy
depends_on:
- php
- pwaIl définit des variables pour la configuration. L’URL de la pwa, les noms de serveurs auxquels répondre, ainsi que deux jetons de sécurité pour le Hub Mercure.
caddy:
build:
context: api/
target: app_caddy
depends_on:
- php
- pwa
environment:
PWA_UPSTREAM: pwa:3000
SERVER_NAME: ${SERVER_NAME:-localhost}, caddy:80
MERCURE_PUBLISHER_JWT_KEY: ${CADDY_MERCURE_JWT_SECRET:-!ChangeThisMercureHubJWTSecretKey!}
MERCURE_SUBSCRIBER_JWT_KEY: ${CADDY_MERCURE_JWT_SECRET:-!ChangeThisMercureHubJWTSecretKey!}Les volumes pour indiquer comment monter le système de fichier au sein du conteneur, et pouvoir persister les fichiers et données de notre application.
caddy:
build:
context: api/
target: app_caddy
depends_on:
- php
- pwa
environment:
PWA_UPSTREAM: pwa:3000
SERVER_NAME: ${SERVER_NAME:-localhost}, caddy:80
MERCURE_PUBLISHER_JWT_KEY: ${CADDY_MERCURE_JWT_SECRET:-!ChangeThisMercureHubJWTSecretKey!}
MERCURE_SUBSCRIBER_JWT_KEY: ${CADDY_MERCURE_JWT_SECRET:-!ChangeThisMercureHubJWTSecretKey!}
restart: unless-stopped
volumes:
- php_socket:/var/run/php
- caddy_data:/data
- caddy_config:/config Et enfin l’ouverture de ports pour l’accès depuis notre machine avec les serveurs et services que l’on va exécuter. Très classiquement, vous y retrouverez les ports 80 et 443, en précisant TCP et UDP pour HTTP/2 et HTTP/3 derrière TLS.
caddy:
build:
context: api/
target: app_caddy
depends_on:
- php
- pwa
environment:
PWA_UPSTREAM: pwa:3000
SERVER_NAME: ${SERVER_NAME:-localhost}, caddy:80
MERCURE_PUBLISHER_JWT_KEY: ${CADDY_MERCURE_JWT_SECRET:-!ChangeThisMercureHubJWTSecretKey!}
MERCURE_SUBSCRIBER_JWT_KEY: ${CADDY_MERCURE_JWT_SECRET:-!ChangeThisMercureHubJWTSecretKey!}
restart: unless-stopped
volumes:
- php_socket:/var/run/php
- caddy_data:/data
- caddy_config:/config
ports:
# HTTP
- target: 80
published: ${HTTP_PORT:-80}
protocol: tcp
# HTTPS
- target: 443
published: ${HTTPS_PORT:-443}
protocol: tcp
# HTTP/3
- target: 443
published: ${HTTP3_PORT:-443}
protocol: udpLe fichier dockerfile trouvé dans le répertoire api est construit en multistage. Le stage nommé app_caddy, c’est le dernier. Cela veut dire que docker exécutera toutes les étapes précédentes avant de configurer le serveur. Remontons le flux des informations de bas en haut.
Ce « stage » va lier la configuration locale Caddy au sein de l’espace disque du conteneur.
Le conteneur est un service de Docker qui se charge de démarrer nos « machines » à partir de nos images, d’exécuter nos commandes et scripts, de nous y donner accès par un terminal, et de faire le pont entre les espaces disque internes et externes (les volumes), et le réseau interne et externe. C’est une machine virtuelle qui va utiliser les ressources de la machine hôte, ici, la nôtre.
Le Dockerfile va avant ça copier dans srv/app/public le répertoire public de notre API (qui se trouve aussi être celui fourni par Symfony) issu d’un « stage » précédent : app_php. Au préalable, il aura aussi copié l’exécutable du serveur Caddy qui lui-même provient d’un « stage » app_caddy_builder.
Le « stage » app_caddy_builder compile le serveur avec deux modules. Mercure et Vulcain. Ce sont des modules optionnels, mais pratiques. Si vous n’en avez pas besoin, vous pourrez les supprimer, mais dans l’état c’est complexe parce que la distribution y fait référence dans l’API et dans la PWA. Nous pourrons éventuellement y revenir plus tard, pour le moment incluons-les.
Mercure sert à pousser des messages en temps réel sur HTTP, Vulcain à alléger des ressources complexes à la volée à la demande d’un client HTTP, ainsi que d’indiquer au client HTTP que des ressources annexes sont à télécharger en avance, grâce aux Early Hints. Je vous laisse le temps de lire leurs documentations respectives plus tard, ce n’est pas important pour l’instant.
Pour savoir comment va se comporter Caddy, il va falloir ouvrir son fichier de configuration api/docker/caddy/Caddyfile. Voici ce qu’il décrit :
# faut-il activer le mode debug ?
{
# Debug
{$CADDY_DEBUG}
}
# le ou les noms de domaines qu'il acceptera de prendre en charge.
{$SERVER_NAME}
# active les logs dans la console. Il est possible de personnaliser leur sortie et le roulement pour les épurer dans le temps.
log
# Associe les demandes de documents HTML, de fichiers statiques et de fichiers Next.js,
# à l'exception des chemins d'accès connus de l'API et des chemins d'accès avec extensions gérés par API Platform
# On stock le résultat dans la clé @pwa.
@pwa expression `(
header({'Accept': '*text/html*'})
&& !path(
'/docs*', '/graphql*', '/bundles*', '/contexts*', '/_profiler*', '/_wdt*',
'*.json*', '*.html', '*.csv', '*.yml', '*.yaml', '*.xml'
)
)
|| path('/favicon.ico', '/manifest.json', '/robots.txt', '/_next*', '/sitemap*')`
# une seule route ici, tout va être redirigé
route {
# par défaut servent les fichiers du répertoire public
root * /srv/app/public
# les instructions de configuration du module mercure
mercure {
#...
}
# activation du module vulcain
vulcain
# Ajouter des liens vers la documentation de l'API et vers le Mercure Hub s'ils ne sont pas définis explicitement (par exemple, la PWA).
header ?Link `</docs.jsonld>; rel="http://www.w3.org/ns/hydra/core#apiDocumentation", </.well-known/mercure>; rel="mercure"`
# Désactiver le tracking des topics s'il n'est pas activé explicitement : https://github.com/jkarlin/topics
header ?Permissions-Policy "browsing-topics=()"
# Cette ligne redirige vers la PWA si la règle défini plus haut réponds positivement
reverse_proxy @pwa http://{$PWA_UPSTREAM}
# Sinon on tente de répondre avec PHP
php_fastcgi unix//var/run/php/php-fpm.sock
# Active des méthodes de compression
encode zstd gzip
# Si le fichier demandé existe dans le répertoire public, on le sert directement.
file_server
}Dans ce fichier il y a des variables qui sont insérées. On les reconnait avec les accolades. Par exemple, SERVER_NAME sert à la définition des HOST pour lequel le serveur pourra prendre la main, puis le fichier docker-compose défini les valeurs respectives de localhost et caddy.
Caddy ici c’est le nom, la clé, du service donné dans le fichier docker-compose.yml. Habituellement pour communiquer entre machines on utilise soit une adresse IP, soit un nom de domaine. En interne, les outils comme docker, podman, kubernetes, rancher, swarm, minikube, etc gèrent dynamiquement l’adressage IP, puis ajoutent un alias de chaque service avec leur nom au démarrage, comme ça, nous en interne (du point de vue docker), on va cibler le nom du service c’est plus simple.
Nous comprenons donc que la requête va servir 3 choses. Des fichiers statiques, une PWA, et PHP-FPM.
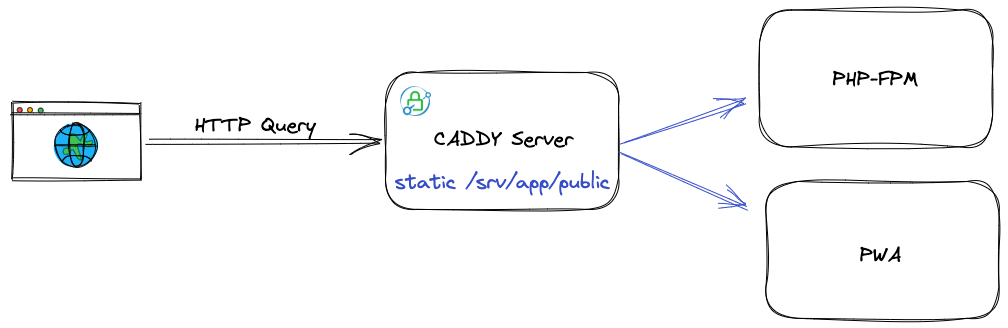
Pour poursuivre, il va falloir choisir entre PWA et PHP-FPM. Puisque nous sommes dans le répertoire API et que nous avons ouvert le Dockerfile associé, attardons-nous un peu dans les parages !
Servir l’API
Retournons sur le fichier docker-compose.yml. De la même manière que le service Caddy, il réclame le Dockerfile du répertoire api en ciblant app_php, dépendant de la base de données, un volume sur le socket PHP pour en faire bénéficier Caddy, enfin des variables de configuration pour cibler la base de données, autoriser les IP et hosts à discuter avec Symfony, l’URL du Hub Mercure et les jetons de sécurité.
Contrairement à un socket TCP/IP qui identifie un serveur par une adresse IP et un port (par exemple, 127.0.0.1:9000), vous pouvez lier un serveur à un socket de domaine UNIX à l’aide d’un chemin de fichier (par example /var/run/php), qui est visible dans le système de fichiers.
Sans rentrer trop dans le détail, voici ce que fait le stage app_php . Depuis l’image de base de PHP 8.2 avec fpm sous alpine, on installe des paquets pour la gestion des droits et des fichiers, git, et fcgi pour PHP. On ajoute des extensions à PHP : zip, apcu et opcache pour la performance, puis intl pour les fonctions d’internationalisation. Enfin l’extension pour PostgreSQL. Vient ensuite la copie des fichiers de configuration de PHP et de fpm, ainsi qu’un script pour vérifier que PHP tourne toujours, à l’aide d’un ping sur la Socket.
Après avoir défini le script à lancer au démarrage avec ENTRYPOINT et la commande à lancer pour maintenir le service en vie avec CMD, on installe composer et toutes les dépendances du projet en mode prod, sans oublier de synchroniser les "recettes » de Symfony.
Si vous poursuivez la lecture, vous trouverez l’ajout de xdebug, de configuration et de variables d’environnement de développement qui ne seront effectives qu’à l’appel du fichier docker-compose.override.yml.
Je ne vais pas détailler les fichiers de configuration, MAIS ! Deux lignes sont un peu plus importantes que les autres : WORKDIR /srv/app. Et oui, rappelez-vous du fichier Caddy. Il précise root * /srv/app/public. Il s’agit du même répertoire. Et COPY --link . ./ pour inclure notre API dans le WORKDIR et donc le répertoire public de Symfony.
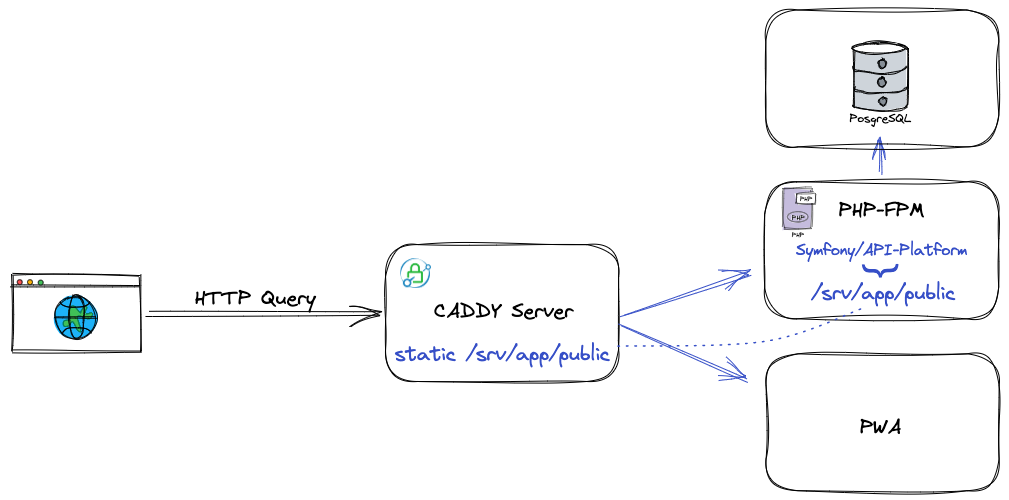
Il nous reste encore un service à explorer.
Servir la PWA
Vous avez pris le pli maintenant, alors voyons le fichier Dockerfile du répertoire pwa.
Le stage prod est le dernier de ce fichier ! Nous allons devoir tout parcourir. Cette fois-ci, nous partons d’une image contenant Node. On copie les fichiers de la PWA, et installe les dépendances. Quelques lignes pour gérer les droits et réaliser quelques optimisations avant d’ouvrir le port 3000 pour Docker.
Cette PWA est une application en React avec une première page nous permettant de nous rediriger vers l’admin (/admin), la documentation SwaggerUI de l’API (/docs) ou l’interface de debug de Mercure (/.well-known/mercure/ui/).
Pour l’admin, il s’agit de React-Admin de chez nos amis de Marmelab. https://marmelab.com/react-admin/.
C’est un admin qui se charge de dynamiquement adapter l’interface selon le contenu de notre documentation OpenAPI ou Hydra fournie par l’API.
À présent que nous avons fait les présentations, il est temps d’utiliser Docker pour accéder à nos services et temps pour moi de vous expliquer quelques mécanismes importants qui simplifieront notre compréhension du déploiement avec Kubernetes.
Ce que nous ferons dans le prochain article.
Merci de m’avoir lu !
—
Chez Les-Tilleuls.coop, nous utilisons GCP et proposons des offres d’accompagnements Kubernetes. Nos consultants et nos SRE pourront vous accompagner sur vos projets :
Nos offres Cloud et DevOps

