
Déployer API Platform sur Kubernetes quand on ne l’a jamais fait – partie 2
Publié le 18 juillet 2023
Version utilisée : 3.1
Attention : Ce ne sera pas facile.
Connaitre le fonctionnement de API Platform n’est pas un pré-requis. Si vous n’avez jamais fait de Kubernetes ou de Docker, pas de souci. Je récapitule quelques concepts ainsi que des fondamentaux lorsque je trouve que c’est nécessaire. Je vais les précéder du symbole :
- Comprendre l’architecture de la distribution API Platform
- Démarrer le projet avec Docker Compose
- Comprendre Kubernetes et l’usage de Helm proposé par API Platform
- Déployer localement avec Minikube
- Déployer sur un vrai Cluster
Dans la partie 1 nous avons étudié ensemble l’architecture de la distribution API Platform. Il est temps de le démarrer sous Docker.
Démarrer le projet avec Docker Compose
Si vous n’avez pas Docker installé, vous trouverez le nécessaire ici : https://docs.docker.com/engine/install/. Ensuite, n’hésitez pas à vous faire aider de vos collègues ou de naviguer sur d’autres blogues.
Les versions récentes de Docker possèdent la commande compose (auparavant un module séparé). Son rôle est de lire les fichiers docker-compose.yml et de lancer les commandes Docker pour nous avec les arguments définis dans les fichiers. Téléchargeons les images demandées dans les fichiers docker-compose.
docker compose pull
[+] Running 12/12
✔ caddy Skipped - No image to be pulled 0.0s
✔ php Skipped - No image to be pulled 0.0s
✔ pwa Skipped - No image to be pulled 0.0s
✔ database 8 layers [⣿⣿⣿⣿⣿⣿⣿⣿] Pulled 34.6s
✔ 08409d417260 Pull complete 1.8s
✔ 6450d4e89514 Pull complete 1.8s
✔ fb127fe040bf Pull complete 1.8s
✔ f852f8e67c59 Pull complete 29.6s
✔ 3ccb7c6f98a1 Pull complete 29.7s
✔ 3ebe1544bc88 Pull complete 29.7s
✔ 431789414521 Pull complete 29.8s
✔ eef368143e0b Pull complete 29.8sSi vous regardez le fichier, la seule image définie ici, c’est PostgreSQL. Bien que les autres définitions se trouvent dans les Dockerfile, elles seront toutes récupérées au moment du build. Vous constaterez que le build va utiliser lesdites images, puis y ajouter les configurations de docker-compose.yml et Dockerfile, et sauvegarder le résultat localement en lui donnant un identifiant unique.
docker compose build
[+] Building 289.5s (46/46) FINISHED
=> exporting to image 0.3s
=> => exporting layers 0.3s
=> => writing image sha256:042e4db4cdbd4890728c1a68bbf59458a296957c97a1f75325e28ccd6abd3b84 0.0s
=> => naming to docker.io/library/api-platform-php
[+] Building 284.2s (40/40) FINISHED
=> exporting to image 0.1s
=> => exporting layers 0.1s
=> => writing image sha256:a2c94fc4bd9c803f56470dcde929521e9c366893be7ee71b0f67abcada9df2c3 0.0s
=> => naming to docker.io/library/api-platform-caddy
[+] Building 94.9s (16/16) FINISHED
=> exporting to image 0.3s
=> => exporting layers 0.3s
=> => writing image sha256:4e1e16e3b6f12d8cd8ad1b641cffc9758b646e00cf225b40cb0980aafcc12022 0.0s
=> => naming to docker.io/library/api-platform-pwaS’il est plus agréable et plus simple de cibler des images avec des numéros de version, ou des noms de tag, une meilleure pratique est de cibler le digest de l’image en question. Par exemple, vous feriez docker pull node:18. Et bien vous devriez plutôt faire docker pull node@sha256:sha_digest. En fait, la raison est la suivante : Vous construisez et déployez votre application dans une CI/CD dans des images docker depuis gitlab ou github. Et sans raison apparente, le job de build échoue. Alors vous vérifiez toute votre application pendant 2h pour aboutir à la conclusion que ça doit venir de l’image ! Dépité, vous vérifiez sur la page officielle, et constatez qu’un commit a été fusionné dans node:18. C’est en vérifiant les logs du pipeline qui échoue, que vous confirmle digest correspond à celui qui est publié et à jour. Le pipeline qui fonctionnait avant est bien avec le digest précédent le commit. Avec le digest plutôt que le tag, vous n’auriez pas eu le problème. Le changement est-il légitime ? Il peut s’agir d’une correction de bug ou d’un CVE critique, je vous laisse libre de juger, surveiller les évolutions de vos dépendances et de les mettre à jour.
Enfin, il est temps de démarrer nos services.
docker compose up --wait
[+] Running 4/4
✔ Container api-platform-pwa-1 Healthy 0.5s
✔ Container api-platform-database-1 Healthy 0.5s
✔ Container api-platform-php-1 Healthy 0.5s
✔ Container api-platform-caddy-1 Healthy 0.5sRegardons le résultat :
docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
api-platform-caddy-1 api-platform-caddy "caddy run --config …" caddy 4 minutes ago Up 3 minutes 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp, 0.0.0.0:443->443/udp, 2019/tcp
api-platform-database-1 postgres:14-alpine "docker-entrypoint.s…" database 4 minutes ago Up 4 minutes 0.0.0.0:5432->5432/tcp
api-platform-php-1 api-platform-php "docker-entrypoint p…" php 4 minutes ago Up 3 minutes (healthy) 9000/tcp
api-platform-pwa-1 api-platform-pwa "docker-entrypoint.s…" pwa 4 minutes ago Up 3 minutes 3000/tcpIci, on constate que Docker a utilisé les images créées localement précédemment, D’ailleurs, il a créé des containers nommés d’après le nom du répertoire dans lequel je me trouve (api-platform) suivi du nom du service et d’un numéro. Sachez que ce nom est configurable.
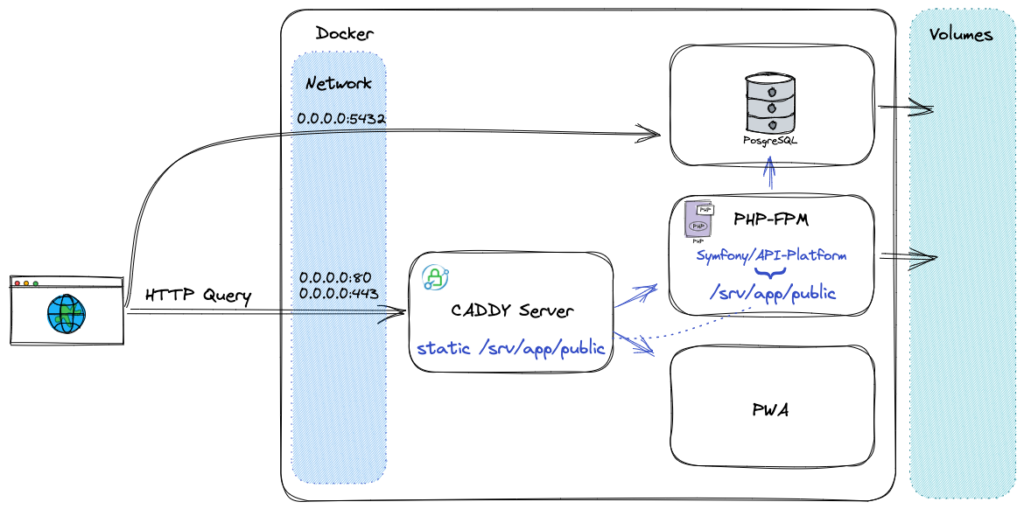
Ensuite, il y a des informations de statuts et de création, et enfin les ports ! Afin de savoir avec qui peut-on discuter. Ici, nous voyons que les seuls accessibles, c’est Caddy sur les ports 80 et 443, et PostgreSQL sur le port 5432.
Pour fonctionner, Docker crée un conteneur. Il isole ce conteneur entièrement par mesure de sécurité. Espace disque comme le réseau. Pour les fichiers ce sont les volumes qui ouvrent une porte avec notre espace à nous. Ils nous permettent de prendre en compte et de conserver les modification lorsque l’on code.
Lors de la publication d’une image pour la production, c’est rare d’avoir besoin d’ouvrir cette “porte » et de monter des volumes. Cela reste vrai pour quelques fichiers spécifiques (configuration, uploads…) mais c’est évitable. Ensuite pour le réseau, c’est pareil. Un conteneur isolé ne peut parler à personne, pas même d’autres conteneurs.
Pour qu’ils discutent entre eux, Docker compose nous prémâche le travail. Il sait que ça va arriver alors il crée un réseau commun et les y inscrit. Ensuite, il va associer un alias portant le nom du service et l’associer avec l’adresse IP assignée lors du démarrage. Et enfin pour que nous y ayons accès, il ouvre les ports spécifiés dans la configuration sur 0.0.0.0. Cette IP symbolise « une route qui mène vers l’extérieur ».
C’est comme ça que je repère les services joignables, sans avoir besoin d’éplucher la configuration.
Si je tente directement de joindre https://localhost/ depuis un navigateur, je vais passer donc par Caddy. Puisque mon navigateur soumet les entêtes nécessaires pour cibler la PWA, c’est là que je vais arriver. Mais si c’est mon premier lancement, alors j’ai d’abord une erreur de certificat.
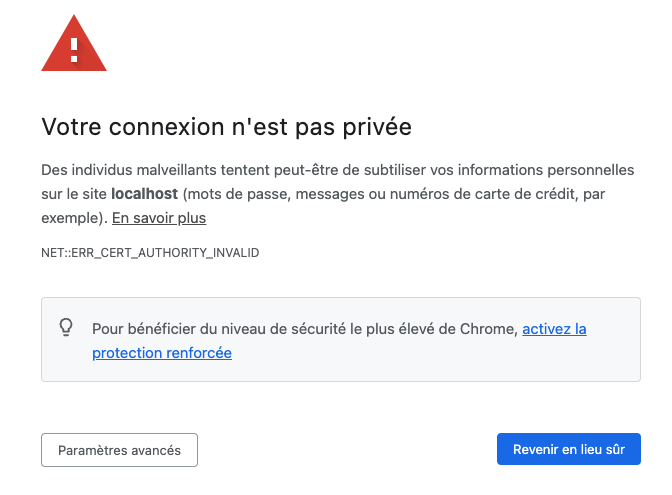
Caddy, sans que j’aie à le lui demander, créé des certificats TLS pour le domaine localhost. Bien que valides, ces certificats ne sont pas enregistrés (ni forcé ou injecté). C’est pour cela qu’il faut les accepter manuellement (ici avec le bouton « Paramètres avancés »).
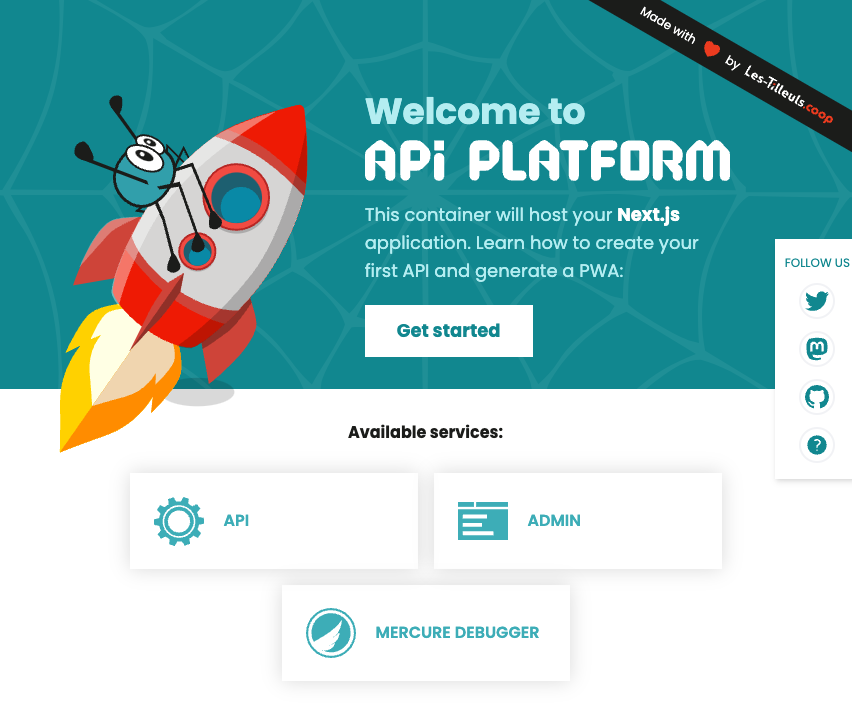
Nous voilà sur l’accueil de la pwa en NextJS. Nous y retrouvons l’API, Mercure et l’Admin (incluse au sein de l’application NextJS).
Et enfin pour obtenir l’API, il faut exécuter un appel HTTP.
curl -X 'GET' \
'https://localhost/greetings?page=1' \
-H 'accept: application/ld+json'Ce qui nous offre ce résultat :
{
"@context": "/contexts/Greeting",
"@id": "/greetings",
"@type": "hydra:Collection",
"hydra:totalItems": 0,
"hydra:member": []
}
Bien, nous avons tous le cheminement en tête. Maintenant, il faut adapter notre vocabulaire docker-ien en kubernetes-ien. Ce que nous ferons dans le prochain article.
Merci de m’avoir lu !
—
Chez Les-Tilleuls.coop, nous utilisons GCP et proposons des offres d’accompagnements Kubernetes. Nos consultants et nos SRE pourront vous accompagner sur vos projets.
Nos offres Cloud et DevOps

