
Construire une application multi-tenant avec API Platform, Symfony et Doctrine (partie 3)
Publié le 12 juin 2024
Dans cet article nous testerons et analyserons l’implémentation de notre architecture multi-tenant dans une application utilisant Symfony, Doctrine et API Platform. Le détail d’implémentation est disponible dans ce précédent article, nous vous recommandons d’aller le lire afin de comprendre le contexte et les objectifs fixés.
Rappel
Comme nous vous l’expliquions dans les deux précédentes parties, notre mission est de proposer à nos agences la possibilité de gérer leurs stocks et garder des traces des livres tout en offrant le cloisonnement des données.
Testons la solution
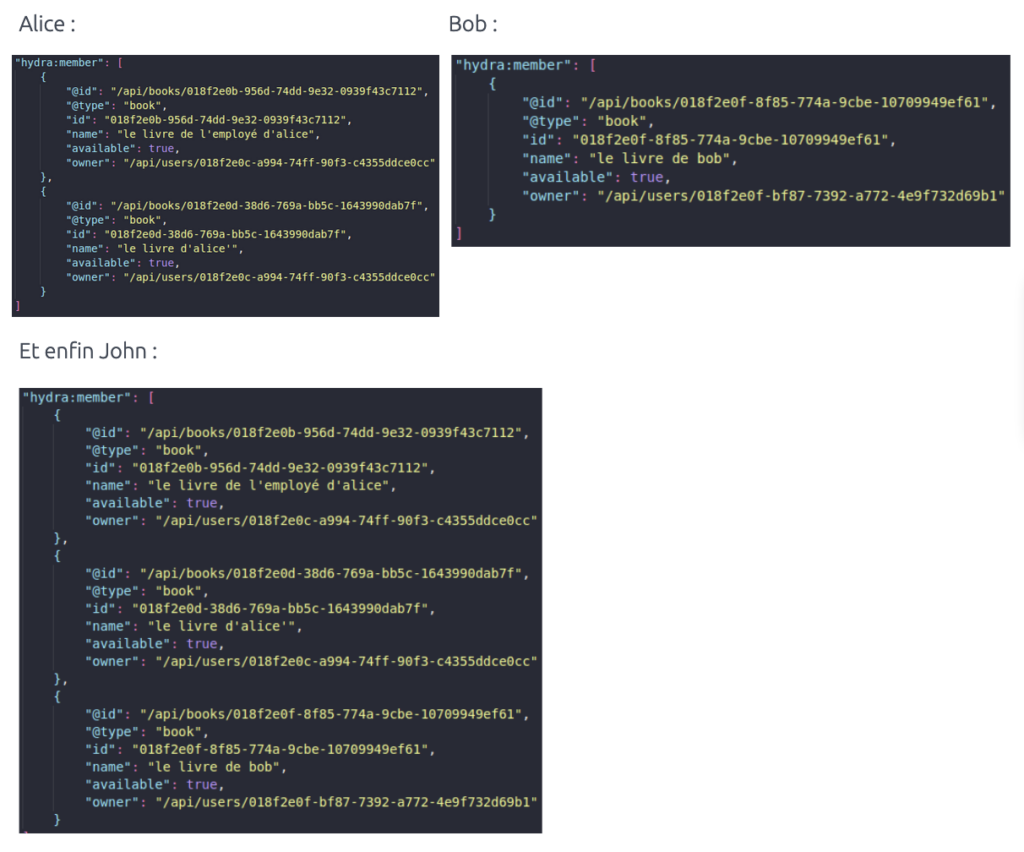
Prenons le scénario suivant : John est le PDG de notre entreprise et souhaite donc mettre en place des bibliothèques privées au sein de ses différentes agences. Alice et Bob étant chefs d’agences, leur compte sera tout deux propriétaire d’une base de données respective.
John est donc un utilisateur ayant le rôle SUPER_ADMIN capable de voir les ressources de tout le monde. Alice et Bob ne verront uniquement celles créées par eux et leurs employés respectifs.
Voici ce que verront les utilisateurs lors d’une requête GET sur l’endpoint livres généré par API Platform.
Sécuriser notre implémentation
Jusqu’à maintenant, nous nous sommes souciés uniquement de la partie fonctionnelle de l’application. Cependant, si nous souhaitons avoir une solution viable, il est important qu’elle soit robuste et sécurisée.
Stockage centralisé
Comme nous l’avons vu précédemment, notre séparation des données n’est que virtuelle aux yeux des utilisateurs, en réalité, toutes nos ressources se situent au même endroit.
On est donc en droit de se demander : “Est-ce que cela représente un risque ?”
Et bien en réalité, pas tant que ça. Comme nous l’avons vu précédemment, chaque client possède son propre utilisateur ayant uniquement les droits sur ses vues, il lui est donc impossible de pouvoir lister le contenu d’autres tables même en profitant d’une potentielle faille d’injection SQL.
Ainsi, le risque que représente cette centralisation des données serait le cas où un individu malveillant arriverait à se connecter en tant que super utilisateur de notre serveur PostgreSQL, mais si ce cas venait à arriver, nous aurions surement d’autres soucis à se faire.
Utilisation des vues
L’intégralité de notre solution repose sur l’utilisation des vues afin de cloisonner virtuellement nos données, nous devons donc nous assurer de leur sécurité.
Une vue SQL fonctionne de cette manière :
- La clause
WHERElors de sa création restreint la portée des données visibles. - Si je peux voir une donnée au sein de la vue, je peux l’éditer ou la supprimer.
- Si je peux voir les données d’une table alors je peux insérer une nouvelle ressource sans restrictions sur les champs.
Le problème de cette dernière phrase est le suivant : que se passerait-il si un utilisateur profitait d’une faille SQL pour y insérer un nouveau livre en utilisant l’identifiant d’une autre agence ?
Dans ce cas, la vue laisserait l’utilisateur faire cette action, on pourrait alors se retrouver avec Alice qui ajouterait des livres dans la base de données de Bob.
Bien que ce comportement soit problématique, il reste peu probable. En effet, il faudrait qu’Alice trouve premièrement une faille dans notre application mais aussi qu’elle connaisse l’identifiant (dans notre cas un UUID) de Bob. Cependant, l’un de nos critères est de faire le moins de compromis possible ! Nous allons donc mettre en place une solution pour éviter ça.
PostgreSQL nous offre une fonctionnalité appelée les triggers (déclencheurs en français). Notre idée est donc d’ajouter un déclencheur sur chaque table étrangère créée, qui aurait comme rôle de ré-écrire l’identifiant du propriétaire de la ressource à chaque insertion (logique applicable à l’édition).
Pour mener à bien notre mission, il existe l’événement BEFORE INSERT permettant de brancher le déclencheur afin de modifier les données avant l’enregistrement dans la base. Parfait, on essaye !
CREATE OR REPLACE FUNCTION override_id() RETURNS trigger as \$override_id\$
BEGIN
NEW.owner_id := 'u1';
RETURN NEW;
END;
\$override_id\$
LANGUAGE plpgsql;
Une fois cette fonction créée dans la base de données du client identifié u1, nous pouvons sur chacune de ces tables enregistrer le déclencheur permettant de l’appeler :
CREATE OR REPLACE TRIGGER livres_override_id
BEFORE INSERT ON "livres"
FOR EACH ROW EXECUTE PROCEDURE override_id();
🥳 Nous voilà maintenant protégés de cette faille ouverte par l’utilisation des vues SQL !
De plus, cet ajout nous offre plus de confort : nous n’avons plus besoin de gérer l’attribut “owner” dans notre application Symfony, le SGBD s’en occupe ! On le passe en GeneratedValue dans notre code et hop, plus besoin de le remplir à chaque création.
Quid des performances
Par définition, l’utilisation de tables étrangères implique une baisse de performance.
Lorsque nous exécutons une requête sur une table étrangère, elle est envoyée à la base de données distante qui nous retourne un curseur sur les lignes de la table pour ensuite traiter la requête localement en récupérant les données 100 par 100 (le curseur tient compte de la clause WHERE) . On pourrait donc s’attendre à ce que sur un gros volume de données, les performances diminuent de plus en plus.
L’un de nos objectifs étant de faire le moins de compromis possible, on se pose donc la question de l’impact que notre implémentation a sur les performances. Est-ce significatif ?
Afin de répondre à la question, nous avons fait des tests de performance à l’aide d’Apache Bench sur une même base de données, avec et sans utilisation de tables étrangères.
Voici les résultats obtenus sur une requête effectuant une jointure, renvoyant 15kb de données en interrogeant deux tables avec un peu plus de 100 000 lignes :

D’après nos tests, nous avons un peu moins d’une milliseconde d’écart entre chaque requête HTTP. Nous estimons que dans notre cas précis, cette différence n’est pas significative comparé aux avantages que nous offre notre implémentation.
Si les performances sont absolument vitale pour votre application et que vous possédez un très très grand nombre de données, quelques pistes d’améliorations pourraient être :
- Augmenter le nombre de données retournées par le curseurde l’extension.
- Mettre en cache certaines tables distantes majoritairement utilisées pour de la lecture et les mettre à jour avec le nouvel ordre MERGE.
- Utiliser des CTE afin de réduire le nombre de données retournées par la connexion fdw distante.
Conclusion
Durant ces trois articles nous avons parcouru différentes pistes afin d’intégrer une architecture multi-tenant au sein d’une application conçue avec Symfony + API Platform avec Doctrine.
Bien que nous soyons contents de la solution que nous mettons en avant, gardez en tête que ce n’est qu’un exemple d’implémentation qui répond à nos contraintes fixées mais qu’il existe d’autres alternatives potentiellement plus intéressantes.
Petit plus : gardant le comportement natif de Symfony, cette implémentation est compatible avec différents outils comme EasyAdmin, API Platform Admin et pleins d’autres !
Si vous souhaitez en apprendre plus sur les architectures multi-tenant, nous vous conseillons de visionner la conférence de Tugdual Saunier où il explore plus en largeur la théorie des différentes possibilités d’implémentation. De notre côté, nous restons à votre disposition pour tous vos besoins d’expertise en PHP, Symfony ou API Platform !


