
Sortie de Vulcain 1.0 !
Publié le 19 octobre 2023
Traduction de https://github.com/dunglas/vulcain
Nous sommes très heureux d’annoncer la disponibilité immédiate de la version 1.0 de Vulcain !
Vulcain est un protocole utilisant les Preload Hints, le code de statut HTTP 103 Early Hints ou HTTP/2 Server Push pour créer des API REST pilotées par les clients. Un serveur de passerelle Open Source que vous pouvez placer devant toute API Web existante pour la rendre instantanément compatible avec Vulcain est également fourni. Vulcain supporte les APIs hypermédias mais aussi toute API “legacy” en documentant ses relations à l’aide d’OpenAPI.
Ce protocole est maintenu dans ce dépôt Github. Un serveur passerelle de référence, prêt pour un déploiement en production, est également disponible. C’est un logiciel libre (AGPL) écrit en Go et basé sur le serveur web Caddy. Une image Docker est fournie.
Introduction au protocole
Au fil des années, plusieurs formats ont été créés pour résoudre les problématiques de performance impactant les APIs : l’over fetching, l’under fetching, le problème N+1… Les solutions actuelles pour contourner ce problème (GraphQL, ressources intégrées, sparse fieldsets de JSON:API…) sont des network hacks pour HTTP/1 qui présentent (trop) d’inconvénients en ce qui concerne le cache HTTP, les logs et même la sécurité.
Heureusement, grâce aux nouvelles fonctionnalités introduites dans la plateforme web, il est maintenant possible de créer de véritables API REST corrigeant ces problèmes avec facilité. C’est là que Vulcain entre en jeu ! Découvrez en version originale la comparaison entre Vulcain et GraphQL, et d’autres formats API.
Pousser des relations
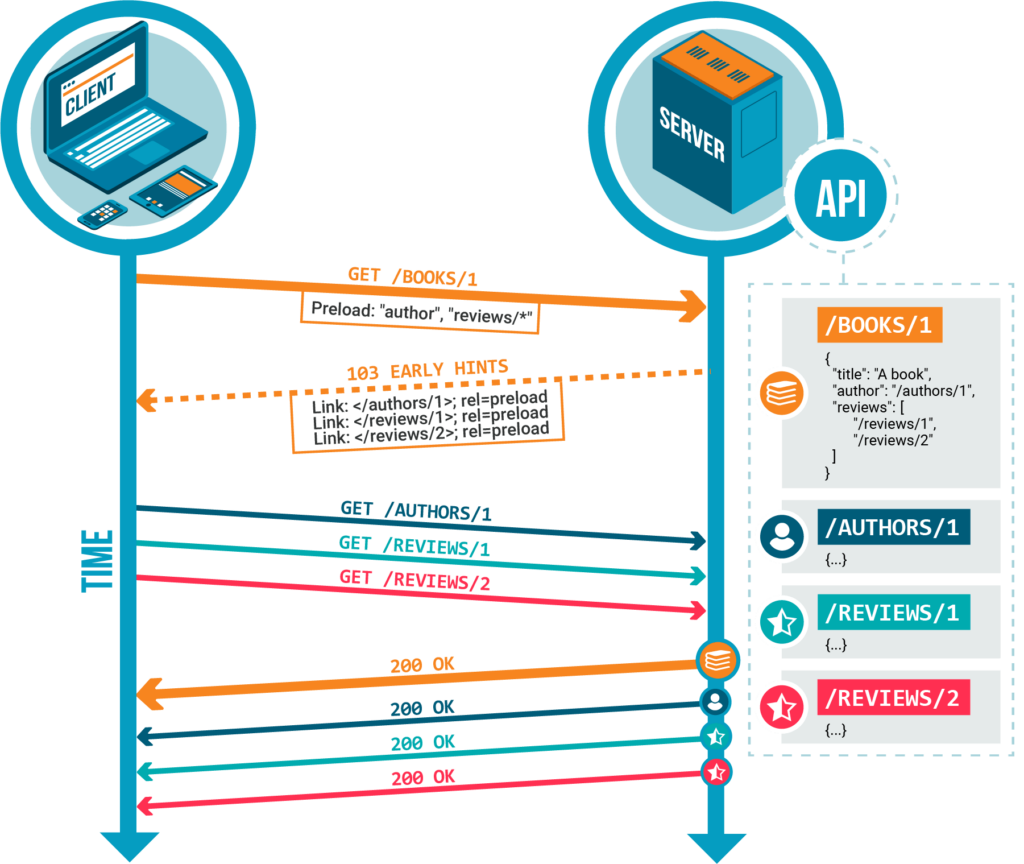
Considérons les ressources suivantes :
/books
{
"member": [
"/books/1",
"/books/2"
]
}/books/ 1
{
"title": "1984",
"author": "/authors/1"
}/books/ 2
{
"title": "Homage to Catalonia",
"author": "/authors/1"
}/authors/1
{
"givenName": "George",
"familyName": "Orwell"
}L’en-tête HTTP Preload introduit par Vulcain peut être utilisé pour demander au serveur de pousser immédiatement les ressources liées à celle demandée en utilisant les Preload Hints (avec ou sans le code HTTP 103) ou le Server Push d’HTTP/2 :
GET /books/ HTTP/2
Preload: "/member/*/author"En plus de /books/, un serveur Vulcain utilisera le Server Push HTTP/2 pour pousser les ressources /books/1, /books/2 et /authors/1 ! Voici un exemple en JavaScript :
const bookResp = await fetch("/books/1", { headers: { Preload: `"/author"` } });
const bookJSON = await bookResp.json();
// Retourne immédiatement, la ressource a été poussée et se trouve déjà dans le cache de push
const authorResp = await fetch(bookJSON.author);
// ...Voici l’exemple complet, incluant les collections. Voir aussi comment utiliser GraphQL comme langage de requête pour Vulcain.
Grâce au multiplexage HTTP/2 et 3, les réponses poussées seront envoyées en parallèle.
Lorsque le client suivra les liens et émettra une nouvelle requête HTTP (par exemple en utilisant fetch()), la réponse correspondante sera déjà en cache, et sera utilisée instantanément !
Pour les APIs non hypermédia (lorsque l’identifiant de la ressource concernée est une simple chaîne de caractères ou un entier), vous pouvez utiliser une spécification OpenAPI pour configurer les liens entre les ressources. Autre conseil : la façon la plus simple de créer une API hypermédia est d’utiliser le framework API Platform dont nous sommes également les créateurs.
Vulcain génère automatiquement vers des liens preload, qui peuvent être utilisés avec le code HTTP 103, et peut utiliser Server Push.
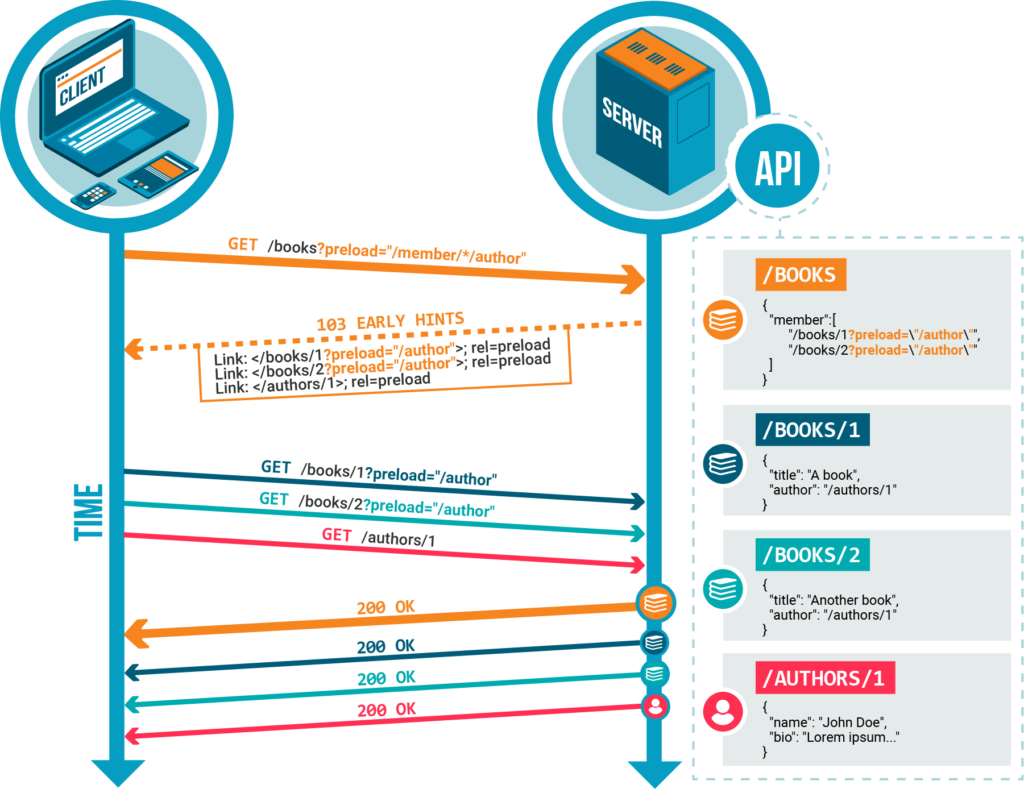
Paramètre de requête
Alternativement aux en-têtes HTTP, le paramètre de requête preload peut être utilisé :
Filtrage de ressources
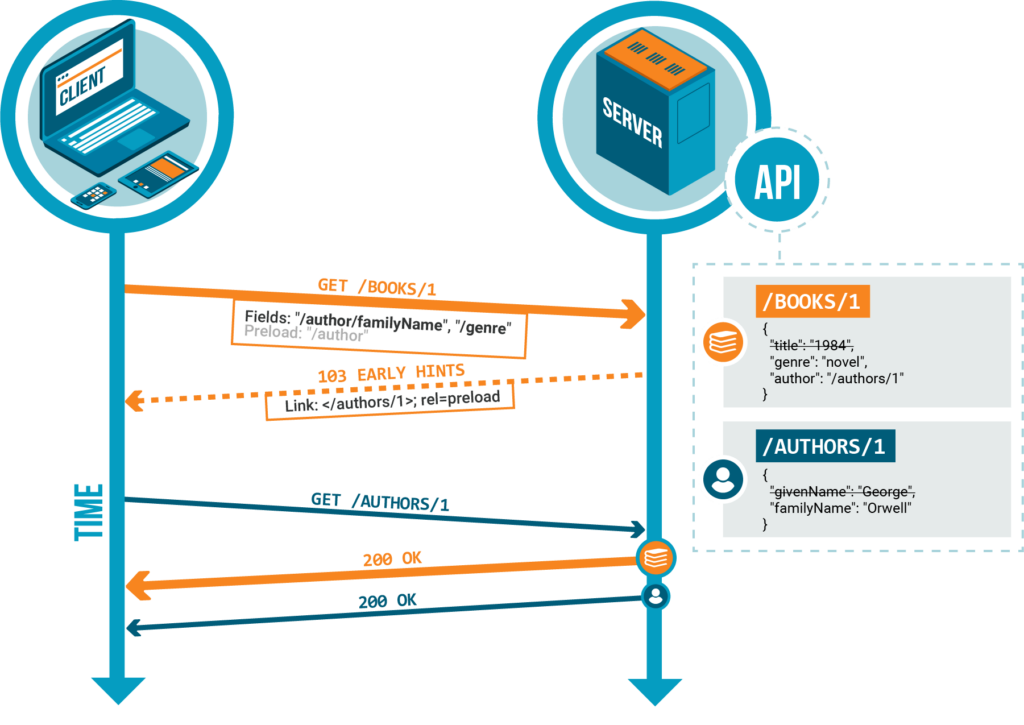
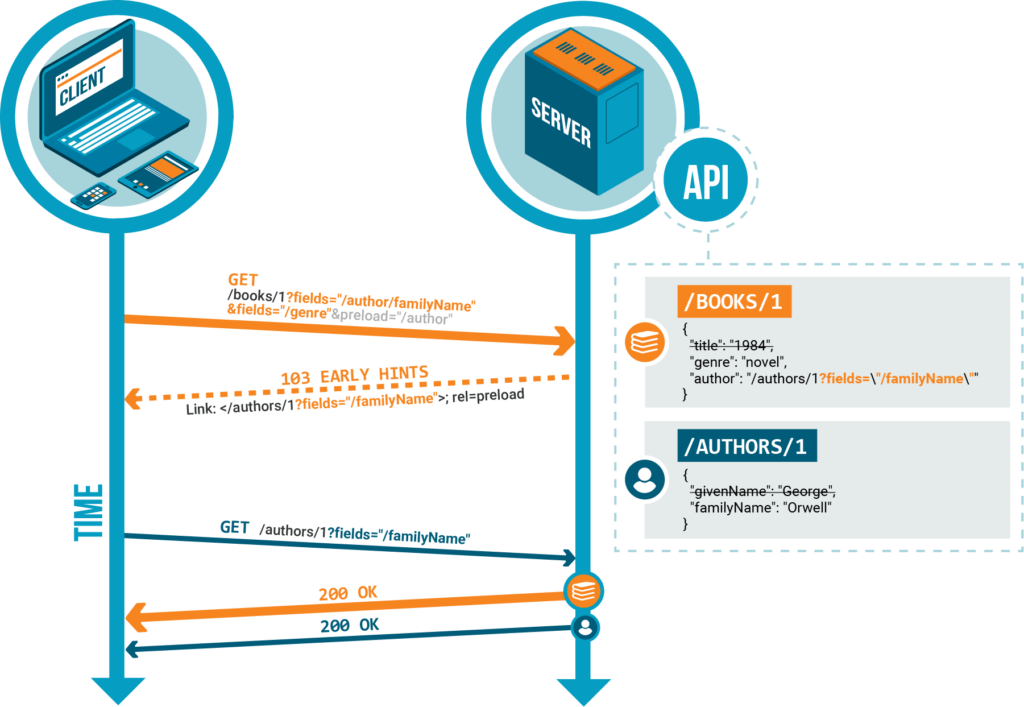
Le header HTTP Fields permet au client de spécifier au serveur les champs de la ressource demandée à retourner (idem pour les ressources connexes préchargées). Plusieurs headers HTTP Fields peuvent être passés. Tous les champs correspondant à au moins un de ces en-têtes seront renvoyés. Les autres champs de la ressource seront omis.
Considérons les ressources suivantes :
/books/1
{
"title": "1984",
"genre": "novel",
"author": "/authors/1"
}/authors/1
{
"givenName": "George",
"familyName": "Orwell"
}Et la requête HTTP suivante :
GET /books/1 HTTP/2
Preload: "/author"
Fields: "/author/familyName", "/genre"Un serveur Vulcain renverra une réponse contenant le document JSON suivant :
{
"genre": "novel",
"author": "/authors/1"
}Il poussera également la ressource filtrée /authors/1 suivante :
{
"familyName": "Orwell"
}Paramètre de requête
Alternativement aux headers HTTP, le paramètre de requête fields peut être utilisé pour filtrer les ressources :
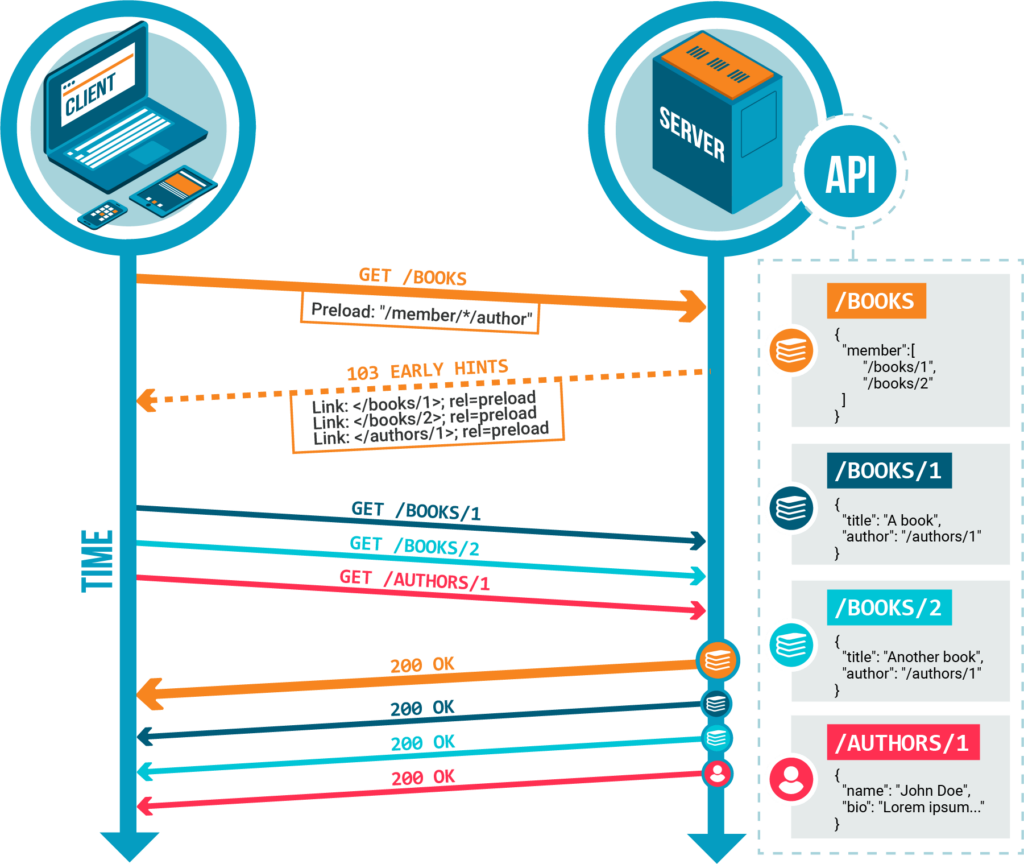
Mapper une API non-hypermédia en utilisant OpenAPI
Bien que l’utilisation des URLs comme valeur pour les liens soit toujours préférable, dans la plupart des API REST existantes, les liens entre les ressources sont connus par le serveur mais ne sont pas fournis dans la réponse HTTP.
Le serveur de passerelle de référence de Vulcain peut malgré ça être utilisé pour ces APIs. Pour ce faire, une spécification OpenAPI (anciennement connue sous le nom de Swagger) décrivant les liens entre les ressources à l’aide d’objets Link doit être fournie.
Imaginez une API web ayant la structure suivante :
/books/1
{
"title": "1984",
"author": 1
}/authors/1
{
"givenName": "George",
"familyName": "Orwell"
}Le lien entre books et les authors, bien qu’il ne soit pas explicitement représenté par une URL, peut être documenté dans un fichier OpenAPI v3 :
# openapi.yaml
openapi: 3.0.0
# ...
paths:
'/books/{id}':
get:
# ...
responses:
default:
links:
author:
operationId: getAuthor
parameters:
id: '$response.body#/author'
'/authors/{id}':
get:
operationId: getAuthor
responses:
default:
# ...Ensuite, utilisez la variable d’environnement OPENAPI_FILE pour référencer le fichier OpenAPI :
UPSTREAM='http://your-api' OPENAPI_FILE='openapi.yaml' ADDR=':3000' KEY_FILE='tls/key.pem' CERT_FILE='tls/cert.pem' ./vulcain
En réponse à cette requête, les ressources /books/1 et /authors/1 seront poussées par le serveur de passerelle Vulcain.
GET /books/1
Preload: "/author"Créer des liens à partir des collections
Le serveur de passerelle Vulcain prend en charge la syntaxe JSON Pointer étendue, pour créer des liens entre les éléments d’une collection et une ressource connexe :
/books
{
"elements": [
1,
2,
3
]
}/books/1
{
"title": "1984",
"author": 1
}Utilisez l’objet links pour lier chaque élément dans la collection :
# openapi.yaml
openapi: 3.0.0
# ...
paths:
'/books/':
get:
# ...
responses:
default:
links:
author:
operationId: getAuthor
parameters:
id: '$response.body#/elements/*'
'/authors/{id}':
get:
operationId: getAuthor
responses:
default:
# ...Avec cette requête HTTP, le serveur poussera toutes les ressources liées à cette collection :
GET /books HTTP/2
Preload: "/elements/*"Réflexions sur le cache
L’un des avantages de l’approche proposé par Vulcain est qu’il permet d’exploiter toute la gamme des capacités offertes par le protocole HTTP, en particulier ses mécanismes de cache et son architecture en couches.
Normaliser l’API pour maximiser les cache hits
Pour libérer toute la puissance de Vulcain, les ressources de l’API doivent être aussi granulaires que possible. Utilisez les liens le plus possible. Par exemple, les collections ne doivent être que des collections de liens, et ne doivent pas imbriquer elles-mêmes les relations. Cela permet d’avoir un cache spécifique pour chaque ressource. Ainsi, lors de la récupération d’une collection, le client n’aura pas besoin de récupérer de nouveau les éléments de cette collection déjà présents dans le cache.
Exemple :
- L’utilisateur arrive sur une page de détail,
GET /book/1, stockée en cache - L’utilisateur clique sur les liens vers la collection,
GET /books/,/bookscontient des liens vers/books/1et/books/2, seul/books/2est récupéré parce que/books/1est déjà en cache.
Utiliser Vulcain avec des serveurs de cache comme Varnish
Vulcain se comporte très bien avec les reverse proxy comme Souin ou Varnish. Une configuration courante consiste à placer le serveur de passerelle Vulcain au bout du réseau pour pouvoir utiliser le Server Push, avec un serveur Varnish derrière lui, et enfin le serveur d’application derrière Varnish.
Les documents complets (non filtrés) doivent être conservés par Varnish. Pour ce faire, Varnish doit enlever les headers Fields et Preload avant de transmettre la requête au serveur back-end. De cette façon, dans la plupart des cas, les ressources seront directement récupérées dans le cache de Varnish (hit) et seront servies presque instantanément au serveur de passerelle Vulcain. Le serveur Vulcain récupérera alors récursivement les relations demandées, et filtrera les documents en supprimant les champs inutiles.
Vulcain se comporte également très bien avec les mécanismes d’invalidation de cache tels que xkey.
Utiliser GraphQL avec Vulcain
Utiliser GraphQL comme langage de requête pour Vulcain
Comme son nom l’indique, GraphQL est avant tout un langage de requête pour les API. Et bien devinez quoi, GraphQL peut être utilisé tel quel avec les serveurs Vulcain ! L’idée principale est d’écrire des requêtes GraphQL côté client, qui seront converties par une bibliothèque JavaScript dédiée en requêtes REST contenant des en-têtes Vulcain.
Pour faire cela, des bibliothèques comme apollo-link-rest peuvent être utilisées. Grâce à apollo-link-rest, vous pouvez écrire votre requête en GraphQL, utiliser tous les outils de l’écosystème front-end s’appuyant sur GraphQL, mais laisser la bibliothèque envoyer des requêtes REST au serveur Vulcain pour répondre à la requête GraphQL.
Cette approche résout également tous les problèmes liés à l’utilisation de GraphQL côté serveur !
Remarque : une bibliothèque dédiée à Vulcain est en cours d’écriture.
Typage et introspection
Vulcain se concentre sur la résolution des problèmes d’under fetching et over fetching. Il n’est pas du ressort de Vulcain de fournir un système de types et un mécanisme d’introspection. Cependant, Vulcain a été conçu pour fonctionner avec les formats existants qui offrent ces possibilités.
Pour les API hypermédias, nous vous recommandons fortement d’utiliser JSON-LD avec le vocabulaire Hydra Core. Pour les API non-hypermédias moins avancées, nous recommandons OpenAPI (anciennement connu sous le nom de Swagger).
Abonnements
Vulcain ne fournit pas un moyen de pousser de nouvelles versions de ressources en temps réel, cependant il fonctionne très bien avec Mercure, un remplacement moderne et RESTful des abonnements WebSockets et GraphQL.
Utiliser d’autres sélecteurs tels que XPath et CSS pour les documents n’étant pas en JSON
Les sélecteurs
Les sélecteurs utilisés comme valeur des headers HTTP Preload et Fields dépendent du Content-Type de la ressource demandée. Cette spécification définit des formats de sélection par défaut pour les types de contenu courants, ainsi qu’un mécanisme permettant d’utiliser d’autres formats de sélection.
Le client DEVRAIT utiliser le header HTTP Accept pour rechercher la ressource dans un format compatible avec les sélecteurs utilisés dans les headers HTTP Preload et Fields.
GET /books/12
Accept: text/xml
Prefer: selector=css
Fields: "brand > name"Si aucune préférence explicite n’a été transmise, le serveur DOIT supposer que le format du sélecteur est le format par défaut correspondant au format de la ressource. Le tableau suivant définit le format du sélecteur par défaut pour les formats courants :

Le client et le serveur peuvent négocier l’utilisation d’autres formats de sélecteur en utilisant l’en-tête HTTP Prefer.
Extension de JSON Pointer
Pour les documents JSON, le format de sélection par défaut est JSON Pointer [@!RFC6901]. Cependant, JSON Pointer ne fournit pas de mécanisme permettant de sélectionner des collections entières. Cette spécification définit une extension du format JSON Pointer permettant de sélectionner chaque élément d’une collection, le caractère *.
Considérons le document JSON suivant :
{
"books": [
{
"title": "1984",
"author": "George Orwell"
},
{
"title": "The Handmaid's Tale",
"author": "Margaret Atwood"
}
]
}Le pointeur JSON /books/*/author sélectionne le champ author de chaque objet du tableau books.
Le caractère * est échappé en l’encodant comme la séquence de caractères ~2. De par sa conception, ce sélecteur est simple et limité. Des sélecteurs simples permettent de limiter plus facilement la complexité des requêtes exécutées par le serveur.
Paramètres de requêtes
Une autre option offerte aux clients consiste à utiliser les paramètres de requête (query strings) de l’URI requêtée pour passer les sélecteurs de champs et de pré-chargement.
Les paramètres preload et query PEUVENT être utilisés pour passer les sélecteurs correspondant respectivement aux en-têtes HTTP Preload et Fields. Les valeurs valides de ces paramètres de requête sont exactement les mêmes que celles définies pour les en-têtes HTTP Preload et Fields.
Conformément à la section 3.4 de l’URI RFC [@!RFC3986], les valeurs des paramètres d’interrogation DEVRAIENT être encodées en pourcentage.
Par exemple, la liste des sélecteurs de champs "/title", "/author" et le sélecteur de pré-chargement "/author" passés à l’aide des paramètres de requête donneront l’URL suivante : /books/1?fields=%22%2Ftitle%22%2C%22%2Fauthor%22&preload=%22%2Fauthor%22
Le serveur ne DOIT pas perdre les paramètres utilisés quand il construit les liens de la réponse.
Les headers HTTP Preload et Fields ne sont pas des en-têtes de requête sûrs d’après la spécification CORS. Les paramètres de requêtes, d’un autre côté, permettent d’envoyer des demandes inter-sites qui ne déclenchent pas de requêtes preflight. De plus, les paramètres de requête n’exigent pas que les clients calculent la partie restante du sélecteur lorsqu’ils requêtent des relations
Cependant, la prise en charge des paramètres de requêtes peut être difficile à mettre en œuvre par les serveurs (les liens contenus dans les documents signifiés DOIVENT être modifiés) et générer des URLs difficiles à lire. La modification de l’URI peut également avoir des effets indésirables.
Pour ces raisons, l’utilisation des headers HTTP DEVRAIT être préférée. Le support pour les paramètres de requête est FACULTATIF. Un serveur prenant en charge les paramètres de requête DOIT également prendre en charge les headers HTTP correspondants.
Exemple :
GET /books/?preload=%22%2Fmember%2F%2A%2Fauthor%22 HTTP/2
{
"member": {
"/books/1?preload=%22%2Fauthor%22",
"/books/1?preload=%22%2Fauthor%22"
}
}Exemple utilisant des paramètres :
GET /books/?preload=%22%2Fmember%2F%2A%22%3B%20rel%3Dauthor HTTP/2
{
"member": {
"/books/1?preload=%22%22%3B%20rel%3Dauthor",
"/books/1?preload=%22%22%3B%20rel%3Dauthor"
}
}Calcul des liens côté serveur
Bien que l’utilisation des capacités hypermédia du protocole HTTP via le Web Linking DEVRAIT toujours être préférée, il arrive que les liens entre les ressources soient connus du serveur mais ne soient pas fournis dans la réponse HTTP.
Dans ce cas, le serveur peut calculer le lien côté serveur afin de pousser la ressource correspondante. Ces liens calculés côté serveur PEUVENT être documentés, par exemple en fournissant une spécification OpenAPI contenant des objets Link.
Considérons les ressources suivantes et supposons que le serveur sait que le champ author fait référence à la ressource /authors/{id} :
/books/1
{
"title": "1984",
"author": 1
}/authors/1
"givenName": "George",
"familyName": "Orwell"
}En réponse à cette requête, /books/1 et /authors/1 devraient être poussés.
GET /books/1 HTTP/2
Preload: "/author"À propos de la sécurité
Utiliser le header Preload peut conduire à générer et à pousser un grand nombre de ressources. Le serveur DEVRAIT limiter le nombre maximum de ressources à pousser. La profondeur du sélecteur DEVRAIT également être limitée par le serveur.
Réflexions sur l’IANA
Les champs header Preload et Fields seront ajoutés au registre “Permanent Message Header Field Names” défini dans la RFC [@!RFC3864]. Un registre de sélection pourrait également être ajouté.
Licence et copyright
TL;DR :
- Un logiciel propriétaire peut mettre en œuvre la spécification Vulcain.
- Des logiciels propriétaires peuvent être utilisés derrière le serveur de passerelle Vulcain sans avoir à partager leurs sources.
- Des modifications faites au serveur de passerelle Vulcain doivent être partagées.
- Une licence commerciale est également disponible pour le serveur de passerelle Vulcain.
La spécification est disponible selon les règles de l’IETF en matière de droits d’auteurs. La spécification Vulcain peut être implémentée par n’importe quel logiciel, même les logiciels propriétaires.
Le serveur de passerelle Vulcain est sous licence AGPL-3.0. Cette licence implique que si vous le modifiez, vous devez partager ces modifications. Toutefois, la licence AGPL-3.0 ne s’applique qu’au serveur de passerelle lui-même, et non aux logiciels utilisés derrière la passerelle.
Des licences commerciales sont également disponibles pour les entreprises qui ne veulent ou ne peuvent pas utiliser les logiciels sous licence AGPL-3.0. Contactez-nous pour plus d’informations.
Treeware
Ce package est distribué à partir de Treeware. Si vous l’utilisez en production, nous vous demandons de financer l’achat d’un arbre. En contribuant à la forêt Treeware, vous créez des emplois pour les familles locales et restaurez les habitats de la faune et de la flore.


