
Mercure, Braid, PREP… du nouveau concernant la souscription aux mises à jour des ressources HTTP
Publié le 29 novembre 2023
Retrouvez la version originale de cet article sur cette page.
Introduction
Depuis maintenant 32 ans, le vénérable protocole HTTP est au cœur du fonctionnement du web. Ce protocole permet de récupérer depuis un serveur des “ressources” (tout ce qui peut être nommé peut être une ressource, mais il s’agit souvent de documents) grâce à leur identifiant unique : leur URL.
Depuis 1991, la popularité du web a explosé, au point qu’il peut désormais être considéré comme l’une des épines dorsales de nos sociétés. Avec cet engouement, de nouveaux usages sont apparus et de nombreuses fonctionnalités ont été ajoutées à “la plateforme web” pour les permettre.
L’un des plus populaires de ces nouveaux usages est la mise à jour en temps réel des ressources affichées à l’utilisateur d’un site ou d’une application web. Les utilisateurs attendent par exemple à pouvoir voir en temps réel les modifications effectuées sur un document partagé (une édition collaborative à la Google Docs), ou encore l’état du stock d’un produit vendu sur un site e-commerce, ou encore des réponses aux messages postés sur un forum de discussion en ligne.
Vous téléchargez donc une “ressource” (le document partagé, la fiche produit ou le message sur le forum) depuis un serveur et elle est affichée par votre navigateur. Mais que se passe t-il si cette ressource est modifiée ou enrichie par son auteur ou par un autre utilisateur après que vous l’ayez téléchargé ? Comment notifier les utilisateurs consultant cette ressource qu’elle a changé. Encore mieux, peut-on envoyer directement aux utilisateurs les modifications qui ont été apportées à cette ressource, afin que leurs navigateurs les affichent en temps réel ?
Malheureusement, même les versions les plus récentes de HTTP (HTTP/3, HTTP/2…) ne proposent pas nativement cette fonctionnalité.
Au fil du temps, plusieurs techniques et protocoles ont été développés pour pouvoir maintenir des connexion persistantes entre le client et le serveur : Comet (1996, maintenant obsolète), Server-Sent Events (2004), WebSocket (2008) ou encore WebTransport (toujours en cours de développement). Toutes ces techniques présentent différents avantages et inconvénients, mais toutes ont le point commun d’être relativement bas-niveau et de ne pas avoir été conçues spécifiquement pour pouvoir envoyer les mises à jour d’une ressource préalablement récupérée par HTTP et de nécessiter des efforts considérables de la part des développeurs pour les utiliser pour répondre à ce cas d’usage.
Un protocole sort tout de même du lot : WebSub (2018, successeur de PubSubHubbub de Google). WebSub est un système permettant de s’abonner aux mises à jour effectuées à des ressources web via un mécanisme de web hooks. WebSub soufre cependant d’une limitation importante : il n’est destiné qu’à la communication de serveur à serveur, le serveur souhaitant s’abonner aux mises à jour d’une ressource publiée par un autre serveur expose une URL qui sera appelé en POST par l’émetteur de la mise à jour. Évidemment, un navigateur est un client, pas un serveur, et il ne peut donc pas exposer d’URL qui recevront ces mises à jour.
IETF 118 Prague
Depuis quelques temps, il y a un fort regain d’intérêt autour de l’élaboration d’un standard (ou plusieurs, voir ci-après) permettant aux clients de recevoir les mises à jour des ressources publiées par les serveurs.
Trois propositions de standards ont été soumises à l’IETF lors des dernières années : Mercure, Braid et PREP. Une discussion à ce sujet a d’ailleurs lieu lors de la conférence 118 de l’IETF à Prague. Les trois propositions ont de nombreuses caractéristiques communes : mécanismes haut niveau permettant de s’abonner aux mises à jour d’une ressource HTTP, possibilité de ne transférer que les changements à appliquer à la ressource (patchs) plutôt que la ressource complète, la possibilité de négocier dans quel format doivent être envoyés les mises à jour et la possibilité de ne récupérer que les mises à jour effectuées depuis une version donnée d’une ressource dont disposait déjà le client (réconciliation).
Ces similarités montre que plusieurs équipes indépendantes ont trouvé des solutions similaires pour répondre à un même besoin, ce qui montre que l’émergence d’un standard (ou plusieurs) est à la fois faisable et nécessaire.
Cependant, les trois approches ont aussi des différences que nous allons maintenant détailler.
Braid
Commençons par la plus ambitieuse des trois propositions : Braid.
Braid est en fait bien plus qu’un simple simple mécanisme de pub/sub comme WebSub, Mercure ou PREP. C’est une extension de HTTP qui propose un framework complet de synchronisation des états entre le serveur et les clients.
Comme Mercure et PREP, Braid propose un mécanisme permettant aux navigateurs web de s’abonner aux changements effectués sur des ressources, mais Braid va bien plus loin en proposant aussi un système complet de gestion des versions, un format de patch et un système de fusion (merge) supportant de nombreux algorithmes de gestion des conflits (OT, CRDT etc).
Dans cet article, nous nous concentrerons sur les souscriptions. Voici un exemple d’envoi des mises à jour d’une ressource (ici /chat) via Braid extrait de l’Internet-Draft :
HTTP/1.1 209 Subscription
Subscribe:
Version: "ej4lhb9z78"
Parents: "oakwn5b8qh", "uc9zwhw7mf"
Content-Type: application/json
Merge-Type: sync9
Content-Length: 64
[{"text": "Hi, everyone!",
"author": {"link": "/user/tommy"}}]
Version: "g09ur8z74r"
Parents: "ej4lhb9z78"
Content-Type: application/json
Merge-Type: sync9
Patches: 1
Content-Length: 53
Content-Range: json .messages[1:1]
[{"text": "Yo!",
"author": {"link": "/user/yobot"}]
Version: "2bcbi84nsp"
Parents: "g09ur8z74r"
Content-Type: application/json
Merge-Type: sync9
Patches: 1
Content-Length: 58
Content-Range: json .messages[2:2]
[{"text": "Hi, Tommy!",
"author": {"link": "/user/sal"}}]
Version: "up12vyc5ib"
Parents: "2bcbi84nsp"
Content-Type: application/json
Merge-Type: sync9
Patches: 1
Content-Length: 288
Content-Type: application/json-patch+json
[
{"op": "test", "path": "/a/b/c", "value": "foo"},
{"op": "remove", "path": "/a/b/c"},
{"op": "add", "path": "/a/b/c", "value": []},
{"op": "replace", "path": "/a/b/c", "value": 42},
{"op": "move", "from": "/a/b", "path": "/a/d"},
{"op": "copy", "from": "/a/d", "path": "/a/d/e"}
]Dans les grandes lignes, Braid propose d’introduire un nouvel en-tête de requête HTTP, “Subscribe”, et un code de réponse HTTP “209 Subscription”. Lorsqu’une souscription est créée, une connexion persistante entre le client et le serveur doit être maintenue, et le serveur enverra les changements effectués à la ressource sous forme de patch dans cette connexion.
Comme déjà indiqué, Braid va bien plus loin et spécifie comment passer les informations de version ou les algorithmes de merge à utiliser.
Il est à noter que Braid demandera une adaptation relativement importante des serveurs déjà existants pour être en mesure de supporter ces nouvelles fonctionnalités, ainsi que l’implémentation de nouvelles API dans les navigateurs (qui peuvent être polyfilées).
De plus, même si l’approche semble relativement simple en HTTP/1.1, les choses se corsent lorsque l’on souhaite pouvoir tirer partie des fonctionnalités avancées de HTTP. Par exemple, Braid impose de connaître la taille de chaque mise à jour (en-tête Content-Length) avant de l’envoyer, sinon le client ne pourrait pas savoir quand s’arrête le contenu de la mise à jour en cours et quand commencent les en-têtes de la suivante. Cette contrainte empêche d’effectuer du streaming, ce qui peut être embêtant si l’on envoie des mises à jour de grande taille.
De même, à l’inverse de HTTP/1.1 qui est un protocole texte, HTTP/2 et 3 sont désormais des protocoles binaires, qui permettent quelques optimisations comme la déduplication des en-têtes. Tirer partie de ces optimisations avec Braid demandera probablement des extensions dédiés aux encodages binaires de HTTP/2+ et une adaptation importante des serveurs web, des proxys, des navigateurs et des autres clients HTTP.
Reste que le travail effectué par l’équipe de Braid est impressionnant, et qu’il pourrait bien être l’avenir temps réel du web !
PREP
PREP, pour Per Resource Events Protocol, est une proposition alternative qui vient de la communauté Solid (une spécification visant à permettre la création d’applications web décentralisées dont est l’origine le créateur du web lui-même) et qui a été initialement créée pour permettre de notifier les clients lorsqu’une ressource hébergée par un Pod Solid (un serveur stockant les données des utilisateurs) est modifiée.
Nous avons déjà eu l’occasion de parler de Solid sur ce blog et même eu l’occasion d’implémenter la partie cliente du protocole en PHP. C’est une excellente nouvelle de voir la communauté Solid participer aux discussions afin de standardiser un protocole commun de publication des mises à jour des ressources.
PREP est moins ambitieux que Braid (la spécification Solid couvre une partie des besoins couverts par Braid) et se concentre sur la souscription aux mises à jour. Extrait de l’Internet-Draft :
GET /foo HTTP/1.1
Host: example.org
Authorization: DPoP <token>
DPoP: <proof>
Last-Event-ID: *
Accept-Encoding: gzip
Accept-Events: PREP; accept=message/rfc822; accept-encoding=identity
HTTP/1.1 200 OK
Vary: Accept-Events, Last-Event-ID
Accept-Events: PREP; accept=message/rfc822
Events: protocol=PREP, status=200, vary=accept-encoding
Last-Modified: Sat, 1 April 2023 10:11:12 GMT
Transfer-Encoding: chunked
ETag: 1234abcd
Content-Type: multipart/digest; boundary=next-message
--next-message
Content-Type: message/rfc822
<message>
--next-message--On peut voir que l’approche proposée par PREP est assez similaire à celle proposée par Braid. Plutôt que de préciser la taille de la mise à jour à venir dans un en-tête Content-Length, Braid s’appuie sur le media type multipart/digest (défini dans la RFC 1341 datant de… 1992) qui permet d’embarquer plusieurs messages dans un message principal. Vous l’aurez compris, chaque mise à jour devient un message embarqué dans la réponse principale.
Réutiliser multipart a aussi l’intérêt de régler le problème du streaming (plus besoin de calculer la taille du message avant de l’envoyer), mais semble être du bricolage, et est moins élégant que la solution proposée par Braid.
Le client indique qu’il supporte les mises à jour de type PREP via un nouvel en-tête : Accept-Events.
Point intéressant, ce nouvel en-tête permet au client de négocier avec le serveur le protocole de mise à jour à utiliser. Par exemple, un serveur supportant à la fois PREP et Mercure pourrait envoyer les mises à jour en utilisant l’un ou l’autre des protocoles suivant ce que demande le client via Accept-Events.
Braid et PREP pourraient être l’avenir du web temps réel…
Comme nous l’avons vu, Braid comme PREP s’attaquent à un problème qui existe depuis le début du web, et c’est une très bonne chose. À terme, si ces initiatives aboutissent, la plateforme web pourrait disposer d’un mécanisme natif, élégant et idiomatique pour envoyer les publications d’une ressource.
J’ai d’ailleurs proposé aux auteurs de Braid et de PREP une approche très similaire à la leur, mais encore plus efficace et encore plus sémantiquement correcte.
Plutôt que d’envoyer une réponse spéciale qui elle même contient plusieurs réponses imbriquées (les mises à jour). Une approche similaire, mais plus efficace et à mon avis encore plus élégante pourrait être de s’inspirer du code 103 Early Hints, qui est désormais supporté par Chrome. C’est peu connu, mais il est autorisé par la spécification HTTP d’envoyer plusieurs réponses en réponse à une requête grâce à la classe de code de statuts 1XX. Les 103 Early Hints permettent au serveur d’envoyer des réponses spéciales au client avant la réponse définitive, afin d’indiquer au client – par exemple – quels fichiers JavaScript et CSS il peut commencer à télécharger pendant que le serveur est en train de générer la réponse finale.
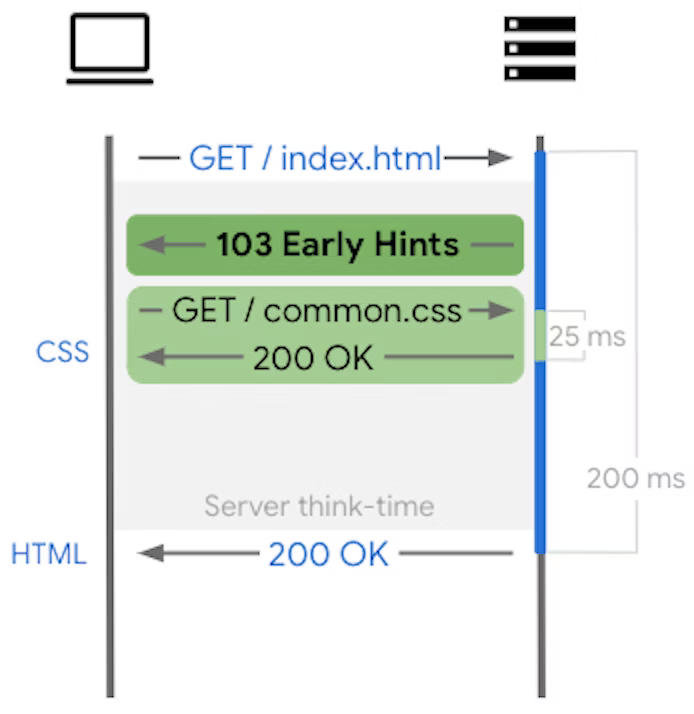
De la même manière, on pourrait imaginer une nouvelle classe de statuts, 7XX, qui permette d’envoyer des réponses après la réponse principale :
Request:
GET /my-resource
Response:
709 Subscription
Content-Type: application/ld+json
{
"baz": "qux",
"foo": "bar"
}
709 Subscription
Content-Type: application/json-patch+json
[
{ "op": "replace", "path": "/baz", "value": "boo" },
{ "op": "add", "path": "/hello", "value": ["world"] },
{ "op": "remove", "path": "/foo" }
]Bien entendu, cela ne peut pas fonctionner en HTTP/1.1, mais Braid comme PREP souffrent de toute façon de fortes limitations quand utilisés avec HTTP/1.1 (voir ci-après). En revanche, il serait tout à fait possible de créer une extension à HTTP/2 et HTTP/3 qui ajouterait un nouveau setting et de nouvelles frames aux protocoles binaires pour permettre cette approche. De plus, toutes les optimisations comme la compression des en-tête seront supportés.
…quand Mercure se concentre sur le présent
Seulement voilà, ces trois propositions ont un parti pris commun : une connexion persistante doit être établie entre le client et le serveur pour chaque ressource. Les mises à jour seront ensuite poussées dans cette connexion.
Le problème de cette approche est qu’elle est extrêmement difficile à déployer dans le web d’aujourd’hui, et que cela risque d’être le cas pendant très longtemps.
En effet, de nombreuses technologies telles que PHP (environ 80% des sites web), les technologies “serverless” comme Amazon Lambda et Cloudflare Worker ou encore les vénérables CGI et FastCGI (qui sont encore eux aussi très utilisés en production) ne sont pas conçus pour, et généralement ne permettent pas de maintenir des connexion persistantes entre le serveur et le client. Toutes ces stacks ont un “timeout” relativement court qui rend impossible, ou en tout cas très difficile le déploiement de ces solutions.
On pourrait imaginer créer des reverse proxies à placer devant les applications utilisant ces stacks qui vont maintenir ces connexions persistantes, mais ils n’existent pas encore et vont représenter une somme considérable de travail pour être implémentés, s’ils le sont un jour. Deuxièmement, ils limiteraient fortement l’intérêt de solutions comme le serverless. Finalement, cela signifierait que l’ensemble du trafic devrait passer par ces reverses proxies, car les souscriptions ne sont pas limitées à une URL spécifique mais peuvent potentiellement être créées à partir de n’importe quelle URL servie par le serveur.
Finalement, ces approches demanderont une adaptation de l’ensemble de l’outillage existant (proxies, WAF, clients HTTP…) pour permettre de prendre en compte ces nouveaux formats, qui nécessitent de lire l’intérieur de la requête HTTP pour en extraire les réponses imbriquées.
D’expérience, l’écriture de serveurs maintenant des connexions persistantes est aussi beaucoup plus difficile : il faut faire très attention aux fuites de mémoire, optimiser le logiciel comme le matériel pour qu’il supporte de très nombreuses connexions en parallèle etc.
Un autre problème de ces approches – même s’il est moins embêtant – c’est que les navigateurs limitent le nombre de connexions persistantes utilisant HTTP/1.1 à 6 (par défaut, 100 sont disponibles en HTTP/2 et 3, et ce nombre peut être négocié entre le client et le serveur).
La spécification Mercure, de son côté, à été conçue dès le départ par Les-Tilleuls.coop pour fonctionner dès aujourd’hui, sans nécessiter de modifier fortement l’outillage existant, et en pouvant s’intégrer très facilement dans les stacks serverless, PHP ou (Fast)CGI.
Dans les grandes lignes, Mercure est une transposition de la spécification WebSub dont on a déjà parlé, sauf qu’elle permet d’envoyer les mises à jours des ressources web au dessus d’une connexion SSE, un mécanisme de connexion persistante supporté par l’ensemble des navigateurs et des proxies depuis très longtemps, simple et ne nécessitant pas de SDK ou de bibliothèque spécifique côté client.
La grande différence entre WebSub, et donc Mercure, et Braid comme PREP, c’est qu’ils proposent de concentrer l’ensemble des mises à jour de ressources sur une seule URL. Un hub, qui peut-être un composant logiciel externe, et qui peut tourner sur du hardware optimisé pour ce type d’usage, va multiplexer les les mises à jour de l’ensemble des ressources sur une seule connexion HTTP.

Mercure ajoute aussi à WebSub la gestion de l’autorisation, basée sur JWT, pour permettre de vérifier qu’un client est autorisé à recevoir la ressource à laquelle il s’est abonné, ainsi que d’un protocole de publication, permettant au serveur d’application de publier une mise à jour temps réel d’une simple requête POST vers le hub.
Bien que Mercure ne soit pas encore standardisé, le protocole est déjà éprouvé : il est utilisé par des centaines de projets en production, dispose d’une implémentation de référence d’un Hub, est open source, très performant, a une communauté très active, 3 500 étoiles sur GitHub et des intégrations dans de nombreux langages et frameworks dont Python, Java, Dart, Symfony et Laravel (PHP) ou encore Hotwired (JavaScript).
Vers un upgrade path
Si on résume, Braid et PREP proposent des protocoles innovants permettant de régler de manière élégante et performante un problème vieux comme le web.
Mercure de son côté propose un protocole, certes beaucoup moins élégant, mais qui reste basé sur les standards du web et – surtout – qui a l’avantage de fonctionner en production dès maintenant.
Et si la solution, c’était deux protocoles ? On ne va pas se leurrer, PHP, serverless et même CGI ne sont pas prêts de disparaître. Et même pour les stacks qui permettent de créer des connexions persistantes, on a vu qu’implémenter et surtout gérer en production dès applications maintenant un grand nombre de connexions persistantes pour potentiellement toutes les ressources du site ne sera pas une mince affaire.
Peut-être que la solution à ce paradoxe a déjà été trouvé par PREP : pouvoir négocier le mécanisme de mise à jour à utiliser (via un en-tête, ou un paramètre HTTP/2+ comme je le propose) qui permettrait aux stacks avancées d’utiliser Braid ou PREP, et les applications plus traditionnelles d’effectuer un “fallback” vers Mercure.
Pour tester Mercure, c’est sur https://mercure.rocks !


