
Introduction à l’architecture RAG
Publié le 13 novembre 2025
Les LLM sont depuis trois ans au centre de toutes les attentions, et malgré des progrès incroyables depuis le buzz de la sortie de ChatGPT 3.5 en 2022, les hallucinations (en gros ces moments où les chatbots IA vous racontent n’importe quoi avec leur meilleur aplomb) sont encore et toujours l’une des principales préoccupations quand on les utilise. Et puis d’un point de vue “professionnel / business”, il faut reconnaître que leurs entraînements fondés quasi exclusivement sur les données publiques sont une énorme limitation. Mais comme tout problème a sa solution, nous allons présenter ici les architectures RAG, et voir comment nous allons pouvoir améliorer (“augmenter”, pour être plus précis) les capacités de génération de nos LLM avec du contenu fiable, sourcé et sur lequel on aura intégralement la main, lui évitant ainsi d’avoir à inventer des réponses tout droit sorties de son chapeau.
Ce sera l’occasion également de vulgariser certains des concepts clés qui existent derrière les IA génératives qu’on utilise au quotidien.

Les hallucinations
Les LLM ne mentent pas, ils n’ont d’ailleurs aucune conscience des notions de vérité ou de fausseté. Les fameuses hallucinations ne sont pas intentionnelles mais une conséquence directe de leur fonctionnement logiciel. Un LLM n’est pas une base de connaissance infinie ou un moteur de recherche (même si les modèles récents des gros acteurs intègrent des fonctionnalités dites de web / deep research), ce sont des modèles probabilistes (en savoir plus en vidéo) : leur fonction est de générer une réponse en prédisant le mot suivant le plus probable dans une séquence de texte donnée.
Sauf que ces probabilités sont calculées à partir de l’entraînement qu’ont suivi les IA : pour faire simple on leur a fait “ingurgiter” des volumes monumentaux de texte (quasiment tout ce qu’Internet contient comme contenu public), et à partir de ces textes, elles ont appris à repérer des patterns et des suites logiques dans ce contenu textuel produit par des humains. Ces motifs repérés leur permettent ensuite de “comprendre” de nouveaux textes mais aussi d’en produire qui seront originaux.
Problème donc : si on aborde un sujet pas ou peu vu lors de l’entraînement, on augmente énormément le risque que les probabilités calculées par le LLM soit approximatives (car basées sur peu de données) et donc que l’IA produise un résultat complètement faux.
Face à ce constat, la question n’est plus « comment empêcher le LLM de mentir? », mais plutôt, « comment faire en sorte de lui éviter d’avoir à inventer? ».
Une solution : la Génération Augmentée par la Récupération (RAG)
Vous l’avez sûrement déjà remarqué, les LLM sont excellents pour comprendre, synthétiser, résumer, reformuler du texte. Par exemple pour cet article, j’aurais pu me contenter d’une simple liste de titres de paragraphes, de quelques phrases écrites à la va-vite, et n’importe quel LLM récent aurait été capable d’en générer un article complet, plutôt bien étoffé, avec une syntaxe impeccable (en tout cas meilleure que la mienne) et sûrement zéro fautes d’orthographe.
Donc gardons cette capacité hors du commun et mettons la à notre profit.
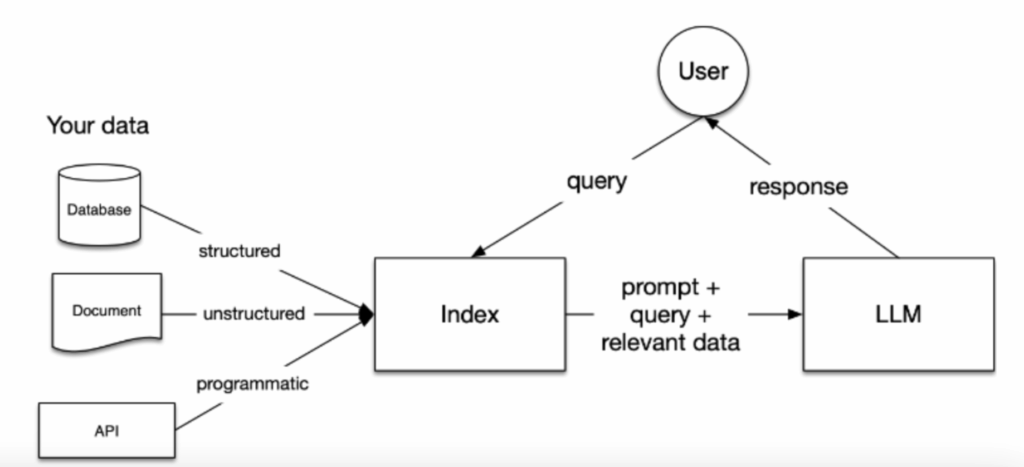
L’architecture RAG est un modèle dont l’idée générale est la suivante : je vais stocker dans une base de données du contenu sur lequel j’ai la main et que je sais fiable (un règlement interne, des CR de réunion, une documentation métier). Ensuite, quand je vais vouloir générer des réponses avec une IA (par exemple un chatbot qui répond à mes clients), je vais aller chercher dans ce contenu stocké les informations pertinentes et les fournir au LLM pour qu’il me génère une réponse améliorée grâce à ces informations vérifiées qu’il n’aurait jamais pu voir lors de son entraînement (parce qu’elles sont privées). On profite donc au maximum de la capacité des LLM à lire, résumer et synthétiser du texte et on compense ainsi ses faiblesses et son absence de connaissance de nos sujets par du contenu que l’on maîtrise et qui sera notre source de vérité.
Vous voyez le potentiel énorme de ce genre de système ? On peut par exemple facilement imaginer et créer un système de chat qui connaîtrait les réponses à 90% des questions récurrentes de notre clientèle (car la réponse serait dans la doc, ou qu’elle a déjà été rencontrée et répondue par un interlocuteur humain dans le passé — et qu’on en a gardé une trace).
À ce moment, normalement vous l’avez compris, RAG est une architecture, un pattern, pas une technologie à proprement parler. On pourrait faire un(e) RAG de plein de manières différentes, mais vous allez le voir dans la suite de cet article, une technologie révolutionnaire surpasse toutes les autres.
Les étapes
Avant de rentrer dans le vif du sujet, on va donc résumer les différentes étapes nécessaires.
- On choisit le contenu qu’on veut mettre à disposition de l’IA (des PDF, des mails, du .doc, des images, des captations vidéos de réunions, etc…).
- On va découper / partitionner de manière logique ce contenu pour pouvoir le stocker dans une base de données et par la suite rechercher en son sein.
- Lorsqu’un utilisateur va nous poser une question, on va utiliser le contenu de sa question pour voir si les thèmes abordés sont présents dans notre base de données.
- À partir de cette recherche on va récupérer les contenus pertinents vis à vis de notre question utilisateur (proximité sémantique entre la question et nos découpages de textes).
On a sélectionné quelques extraits intéressants dans notre BDD qui peuvent aider à générer la réponse, on va les fournir en contexte à notre LLM qui va donc synthétiser tout ça et générer une réponse sourcée
Prenons un exemple concret plus parlant, un chatbot RH interne à une grosse société.
- On récupère le règlement intérieur de la boîte, les statuts, la convention collective, le droit du travail, les accords de branche, etc…
- On découpe tout ça en blocs logiques et on les stocke
- Un employé de l’entreprise veut savoir s’il a le droit de prendre des congés payés dès sa première année
- À partir de sa question “congés / première année”, on va chercher des passages qui pourraient vraisemblablement aborder cette thématique
- On fournit à notre LLM un extrait trouvé dans le règlement intérieur qui précise que dès la fin de la période d’essai un salarié peut demander à consommer ses congés acquis
- Le LLM à partir de cet extrait va générer une réponse adaptée et donc sourcée, en indiquant même d’où vient l’information
La mécanique vectorielle
On en a parlé au-dessus, une technologie extraordinaire permet ce genre de procédé.Imaginons qu’on veuille faire une architecture RAG avec une base de données traditionnelle, on va prendre la question de l’utilisateur et rechercher si les mots de sa question sont présents dans une ligne de notre BDD. Cette approche est limitée : une faute, une abréviation, un synonyme et rien ne ressort d’une simple recherche textuelle.
C’est là qu’intervient le concept de « vectorisation », plus connu sous le nom d' »embeddings ». Pour faire simple, les ordinateurs ne comprennent pas le langage humain, ni la sémantique de nos échanges oraux ou écrits. En revanche, les ordinateurs sont très performants pour comprendre les chiffres. Nous allons donc transformer notre langage en format numérique. L’idée est de capturer le sens d’une phrase, le sujet abordé, et de le convertir en une suite de nombres que l’on pourra stocker. À partir de ces nombres, nous pourrons effectuer des recherches de proximité ou de similarité. Ce procédé, c’est la fameuse vectorisation : nous prenons du texte en entrée et obtenons des centaines (voire des milliers) de nombres flottants en sortie. Chacun de ces nombres permet de capturer, dans une dimension donnée, une partie du sens de la phrase.
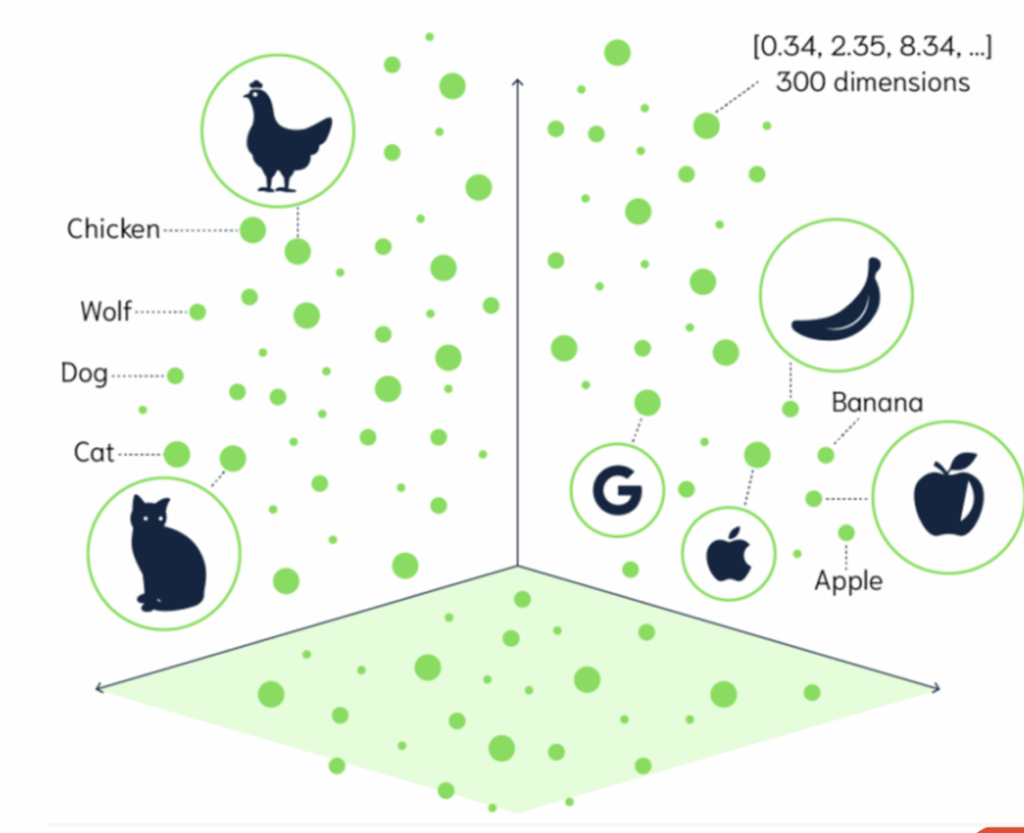
J’aime beaucoup l’analogie du point GPS, ce dernier vous permet, à partir de deux nombres, de vous situer sur deux dimensions : latitude et longitude. Imaginez maintenant avoir un point avec 1500 nombres flottants, chacun capturant la position dans une dimension différente : une qui permette de savoir si le langage est soutenu ou familier, une si le fond parle de sport ou de politique et ainsi de suite.
Ainsi, si demain je vectorise deux articles “Compte rendu de l’API Con 2025” sur deux blogs distincts, en toute logique, leurs représentations vectorielles seront très proches : mêmes thématiques abordées, mêmes sujets, etc… La vectorisation préserve la proximité sémantique : “chat” et “chaton” seraient proches sur une hypothétique carte vectorielle.
On peut même aller plus loin : si vous prenez le vecteur de roi et que vous lui soustrayez le vecteur d’homme pour lui ajouter le vecteur de femme, la somme vectorielle “finale” devrait être assez proche du vecteur de “reine” (roi – homme + femme = reine).
La vectorisation de contenu est une opération de machine learning complexe et très coûteuse en ressources, actuellement aucun outil ne permet de faire ça nativement en PHP. Heureusement pour nous, des dizaines d’acteurs du secteur de l’IA proposent des moyens simples et efficaces pour le réaliser, la plupart de ces derniers disposent même généralement d’endpoint API qui vous permettent de vectoriser vos textes ultra rapidement à des prix très compétitifs.
Si vous voulez vous amuser à tester la vectorisation, Cohere propose une API gratuite permettant d’utiliser leur LLM, leurs modèles d’embeddings, etc… Et ça tombe bien, j’ai publié un SDK en PHP pour l’intégrer facilement dans un projet du même langage.
Stocker ces vecteurs
On a vu comment transformer notre data en vecteurs, il va désormais falloir les stocker, dans ce qu’on appelle communément des “bases vectorielles”. Concrètement des dizaines de solutions s’offrent à nous, mais si on veut rester dans notre zone de confort et intégrer ces derniers facilement dans nos bases de données aucun problème : PostgreSQL dispose d’une extension intitulée pgvector et MySQL depuis sa version 9 dispose d’un type vector et de fonctions qui permettent également de rechercher parmi ces fameux nombres flottants.
Vient ensuite l’étape de la recherche et récupération de ces données, on va faire ici de la recherche sémantique, “par sens” et pas de la simple recherche textuelle ( WHERE = ou LIKE %%)
La métrique la plus courante pour mesurer cette « proximité sémantique » est la similarité cosinus. La similarité cosinus mesure l’angle entre les vecteurs.
L’interprétation des angles est simple :
- Angle faible : Similarité très élevée. Les vecteurs pointent dans la même direction.
- Angle de 90° : Aucune similarité sémantique. Les vecteurs sont perpendiculaires.
- Angle de 180° : Concepts opposés.
Les bases vectorielles mentionnées précédemment proposent toutes des fonctions de recherche qui permettent de mesurer cette proximité sémantique en comparant notre recherche avec les vecteurs déjà stockés.
L’Intégration dans PHP
Exécuter les recherches mentionnées en SQL brut dans notre application PHP est évidemment possible, mais manipuler des vecteurs de 1 536 dimensions sous forme de chaînes de caractères n’est pas idéal.
La bibliothèque pgvector/pgvector-php fournit le pont parfait pour utiliser l’extension dans vos applications : un support natif pour Doctrine et Eloquent qui permet très facilement d’intégrer les vecteurs et la recherche vectorielle dans votre architecture existante.
En parallèle, de nombreuses innovations fleurissent depuis quelques mois dans l’écosystème PHP comme LLPhant ou Symfony AI initiative. Ces dernières vous offrent une panoplie d’outils clés en main pour mettre en place une architecture RAG complète, du chunking (le découpage de vos données) à la vectorisation en passant par la recherche sémantique, ces bibliothèques vous permettent de brancher votre infrastructure à la plupart des grosses solutions IA fournies actuellement par les principaux acteurs du marché, le tout par différents systèmes de bridges qui permettent des interactions simplifiées et généralement cadrées par des interfaces solides.
Si vous voulez en savoir plus, voici les slides de ma conférence donnée en octobre au Forum PHP.
Vous avez besoin d’aide dans vos projets IA ? Les-Tilleuls.coop est à vos côtés que ce soit pour la mise en place de workflow automatisés avec agents IA, ou le développement intégral d’architectures RAG solides, nos experts peuvent vous accompagner à chaque étape de l’élaboration de vos projets. Contactez-nous !


